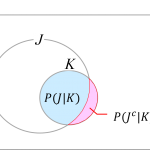
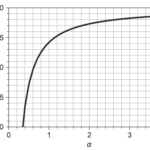
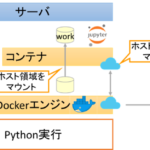
週記(23/01/08週):イルミネーションを見ながらLISの復元に思いをはせる

今週のまとめ イルミネーションを見ながらLISの復元を考える Optuna論文を読んで発表した Grundy数を学んだ ABC285に出た。ちょっと冷えた です。 (本文中にABC 043 D, 222 E, 284 D… 続きを読む »
今週のまとめ イルミネーションを見ながらLISの復元を考える Optuna論文を読んで発表した Grundy数を学んだ ABC285に出た。ちょっと冷えた です。 (本文中にABC 043 D, 222 E, 284 D… 続きを読む »
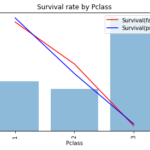
前回の記事ではロジスティック回帰モデルで生存者予測を行いました。 ロジスティック回帰モデルは「目的変数(生存しやすさ)を特徴量の重み付けで表現しモデルの可読性が高い」という利点がある一方で 目的変数と特徴量の間には「単調… 続きを読む »
単変量モデル編では特徴量ごとにロジスティック回帰モデルを構築し精度評価を行いました。ここでは7つの特徴量を使って生存者を予測するモデルを構築します。 今までのモデルと比べ 互いに相関のある複数の特徴量を用いる モデルのハ… 続きを読む »
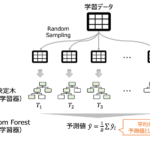
良い機械学習モデルを作るにはモデルの良さを「正しく」評価する必要があります。実際、機械学習プロジェクトでモデルを正しく評価していなかったために 検討時は良いモデルができた(と思っていた) いざ業務で使うと精度が悪くて使い… 続きを読む »
ベースラインモデル編では「Majority classifier」を構築しました。Majority classifierは特徴量を1つも用いずすべて「死亡」と予測するモデルでしたが、ここでは特徴量を1つだけ用いる単変量モ… 続きを読む »
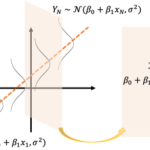
誤差項が独立同一な正規分布に従う場合、「回帰係数の確率分布」の結果から予測区間(Prediction Interval)を構成することができます。 なお、予測区間の意味や解釈の仕方、信頼区間との違いがややこしく誤解しやす… 続きを読む »
誤差項が独立同一な正規分布に従う場合、「回帰係数の確率分布」の結果から信頼区間(Confidence Interval)を構成することができます。 なお、信頼区間の意味や解釈の仕方、予測区間との違いがややこしく誤解しやす… 続きを読む »
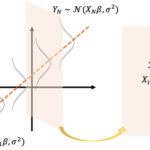
誤差項が独立同一な正規分布に従う場合、「回帰係数の確率分布」で見たように最小二乗推定量[math]\boldsymbol{\hat{\beta}}[/math]と誤差項の分散[math]\sigma^2[/math]の不… 続きを読む »
誤差項が独立同一な正規分布に従う場合 最小二乗推定量[math]\boldsymbol{\hat{\beta}}[/math]が正規分布に従う 分散の不偏推定量[math]S^2[/math]に対し[math](N-P-… 続きを読む »
ここからは誤差項が正規分布に従うモデルを考えます。 [math] \begin{eqnarray} Y_i &=& \beta_0 + \beta_1 x_1 + \cdots + \beta_P … 続きを読む »