良い機械学習モデルを作るにはモデルの良さを「正しく」評価する必要があります。実際、機械学習プロジェクトでモデルを正しく評価していなかったために
- 検討時は良いモデルができた(と思っていた)
- いざ業務で使うと精度が悪くて使い物にならなかった
という話をよく耳にします。
一般に機械学習モデルは未知データで精度が悪化する「過学習」を起こしやすく未知データで性能を測る必要があります。ここでは機械学習モデルの評価方法として
- Train-Test分割
- Train-Test-Validation分割
- 交差検証(クロスバリデーション)
と時系列データでの分割方法である「Out of Time Validation」を紹介します。
Train-Test分割
機械学習モデルが学習データから有用な知見を獲得できたかは
学習データをきちんと当てられるか(学習能力)
だけでは不十分(モデルによっては学習データを「丸暗記」できるため)で
未知データでもきちんと当てられるか(汎化能力)
を評価する必要があります。
データセット全体でモデルを作りたくなりますが、Train-Test分割では
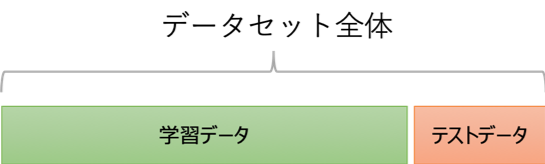
- 学習データ: モデル構築、チューニングに利用
- テストデータ: モデルの最終評価に利用
の2つに分け学習データでモデルを構築し、学習には使っていないテストデータで精度(汎化能力)を評価します。なお、学習データは訓練データ、テストデータはHoldoutデータと呼ばれることもあります。
データの分け方ですが各サンプルが独立と考えられる場合はランダムサンプリングや層別サンプリングを用いますが
- データ間に「グループ」がある場合(製品をバッチ処理するなど)はグループ単位で学習/テストを分割
- 時系列データの場合は後述のOut of timeの考え方で分割
する必要があります。どれくらいの割合で分割するのかはデータセットのサイズにもよるのですがテストデータとして[math]20\%[/math]程度は確保することが多いです。
Train-Test-Validation分割
Train-Test分割はもっとも基本的なデータ分割の考え方ですが、Random Forestなどハイパーパラメタを持つモデルだと
学習データでモデル構築/チューニングすると学習データに対し過学習する
という問題が起きます。

この問題の原因はハイパーパラメタの良し悪しを「学習データの精度」で評価し「未知データの精度」で評価していないことによります。そこでTrain-Test-Validation分割では

- 学習データ: モデル構築に利用
- 検証データ: ハイパーパラメタのチューニングに利用
- テストデータ: モデルの最終評価に利用
と3つに分割します。学習データとは別の検証データでハイパーパラメタの良し悪しを評価することで上記の問題を解消することができます。
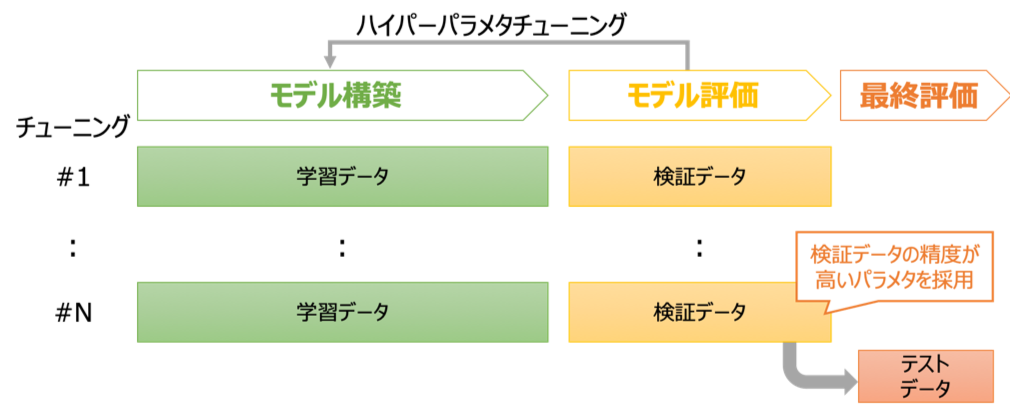
どれくらいの割合で分割するのかはデータセットのサイズにもよるのですが検証データ、テストデータとしてそれぞれ[math]20\%[/math]程度を確保することが多いです。
交差検証(クロスバリデーション)
Train-Test-Validation分割を使うことでモデル構築、ハイパーパラメタのチューニングを適切に行うことができます。ただ、
- データの一部は検証にしか使われない
- 検証データに偏りがあると評価も偏る
- チューニングにより検証データに対して過学習する可能性がある
といった課題もあり特にデータ数が少ない場合は問題になることがあります。
テストデータ以外のデータをすべて使う手法としてK分割交差検証(K-fold cross validation)という手法が知られています。この手法ではテストデータ以外のデータを[math]K[/math]個に分割します。(以下、[math]K=3[/math]とします。)
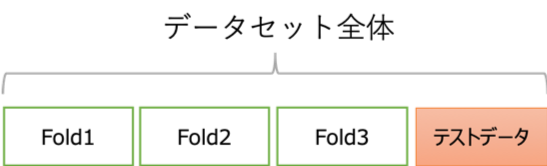
次のモデル構築/評価を[math]K[/math]回繰り返します。
- [math]i[/math]回目のモデル構築: Fold-[math]i[/math]以外のFoldで学習
- [math]i[/math]回目のモデル評価: Fold-[math]i[/math]で精度評価
最後に各モデル評価の平均値を交差検証での精度とし、Fold-1からFold-[math]K[/math]のデータで再学習したモデルを出力します。
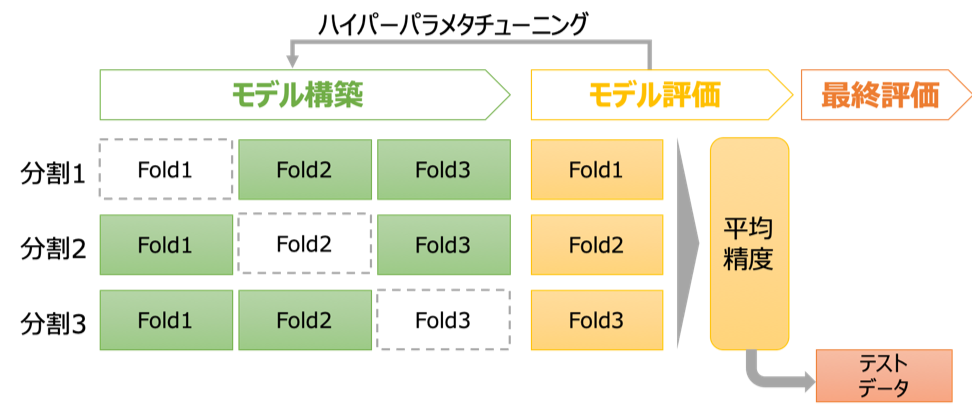
[math]K[/math]を大きくするとモデル構築に使えるデータが増える一方、計算時間が増えるため通常[math]K[/math]は3から10程度にすることが多いです。データが少ない場合は各Foldのデータ数を1にするLeave-one-out交差検証にすることもあります。なお、[math]K[/math]回繰り返すモデル構築/評価は並列計算できるためCPUのコア数で決める[1]4コアのCPUの場合、[math]K=4, 8 , 12[/math]を試すなど。という考え方もあります。
交差検証はTrain-Test分割やTrain-Test-Validation分割と比べ過学習のリスクは少ないですが、それでもFold-1〜Fold-[math]K[/math]のデータに過学習するリスクはあり最終的な評価としてテストデータで過学習していないか確認する必要があります。
Out of Time Validation
データセットが時系列データの場合、時間の流れに沿って因果関係や相関関係、傾向を持つことがよくあります。この場合、単純にランダムサンプリングを行うと学習時点ではわからないはずの「将来の相関、傾向」まで学習したモデルができてしまい精度を過大評価することなります。
そのため時系列データでは学習データと検証/テストデータは
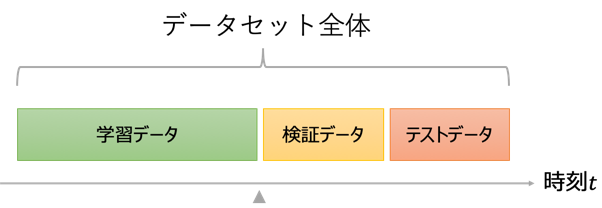
- 学習データ: ある時点からみた「過去」データ
- 検証/テストデータ: ある時点からみた「将来」データ
となるように分割する必要があります。この分割をOut of Time Validationと呼びます。
時刻データがなくても実は「製品の製造順」で傾向があった…といったケースもあるので、陽に日付、時刻といったデータがなくても「時間の流れに沿った傾向」がないかを確認しOut of Time Validationを使うべきか検討することをオススメします。
まとめ
機械学習モデルのデータ分割、評価方法として「Train-Test分割」「Train-Test-Validation分割」「交差検証」と「Out of Time Validation」を紹介しました。使い方のポイントをまとめると次になります。
- テストデータを必ず用意し汎化能力があるか(過学習していないか)を確認する
- 時系列データや時間の流れに沿った傾向がある場合はOut of Time Validationを使う
- データ間にグループがある場合はグループ単位で学習/検証/テストを分割する
- パラメタチューニングを行う場合はTrain-Test-Validation分割または交差検証を使う
脚注
| ↑1 | 4コアのCPUの場合、[math]K=4, 8 , 12[/math]を試すなど。 |
|---|