概要
2012年の画像認識コンペILSVRCでDeep Neural Networkを使い圧勝したAlex Krizhevsky氏の論文です。Deep Learningの出現で職人技と思われていた特徴量設計も機械学習で出来ることが立証され、まさにこの論文が第3次AIブームの火付け役でしょう。
この論文で提案されたモデルは5層の畳み込み層と3つの全結合層を持つ畳み込みニューラルネットワーク(Convolution Neural Network, CNN)で筆頭著者のAlexさんの名前を取ってAlexNetと呼ばれています。その後の発展でAlexNet自体を使う機会は減りましたが、後続のDeep Neural Networkでも広く採用されている
- ReLU活性化関数
- マルチGPUでの学習
- Data augmentation(データ拡張)
- Dropout
などの技術がすでに導入されています。歴史を知るだけなく、今も使われている基礎技術を知ることができる論文です。Alexさんのページから論文のPDFをダウンロードすることが出来ます。
データセット
ImageNetのデータを元にしたILSVRCコンテストのデータ[1]データセットの詳細は「ImageNet(ILSVRC2012)データセット」を参照ください。
- 学習(training): 120万画像
- 検証(validation): 5万画像
- 評価(test): 10万画像
を使用しています。大量かつ良質な教師データが使えるようになったこともDeep Learning成功の背景ですね。
画像の前処理として
- 解像度の正規化: CNNは固定長ベクトルを入力とするため画像を[math]256\times 256[/math]に変更。短辺を[math]256[/math]ピクセルになるように縮尺を変え中心部分の[math]256\times 256[/math]領域を切り出す。
- Per-pixel Mean Substraction: ピクセル・チャンネルごとに平均を出し入力から差し引く。つまり、[math]256\times 256\times 3[/math]個の平均値を出し、各入力画像から差し引く。
をしています。
AlexNetの構造
5層の畳み込み層と3つの全結合層からなる全8層のNeural Networkを学習しています。論文では学習における要素技術を効果が高かった順に説明されています。
ReLU活性化関数
一番効果があったとされているのがReLU活性化関数です。従来、活性化関数として
- シグモイド関数[math]f(x)=(1+e^{-x})^{-1}[/math]
- [math]f(x)=\tanh(x)[/math]
がよく使われてきましたが、AlexNetではRectified Linear Unit(ReLU)関数[math]f(x)=\max (0,\ x)[/math]を採用しています。
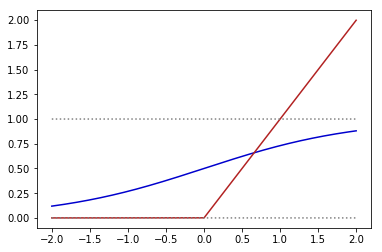
上図の青線がシグモイド関数で赤線がReLU関数です。シグモイド関数だと[math]x[/math]が大きい領域で勾配が0に近づき収束しにくくなる問題(勾配消失問題)が知られていますがReLU関数を用いることで回避しているそうです。CIFAR-10データを4層のNeural Networkで学習した実験では[math]\tanh[/math]関数と比べReLU関数は6倍高速に収束したようです。
マルチGPUでの学習
120万枚の学習データは1枚のGPUに乗りきらないため2枚のGPUで分担して学習しています。どういうネットワーク構造でどう分担するかは「culmnar CNNのようなもの」とだけ書かれており、詳細はよく分かりません。
後続の3.5節”Overall Architecture”を読むと画像の上半分と下半分をそれぞれのGPUで学習していくようなイメージになっています。
Local Response Normalization(LRN)
輝度の平均を0にしていないので輝度の正規化として次のLRNを行う。
[math]
b^i_{x,y}=a^i_{x,y}\left/\left( k + \alpha\displaystyle\sum_{j=\max(0,i-n/2)}^{\min(N-1,i+n/2)}(a^j_{x,y})^2 \right)^\beta \right.
[/math]
要は「同一ピクセルにおいて複数の特徴マップ間で正規化する」ということをしているのですが、これが輝度の正規化になるかはまだ理解が追いついていません…
Overlapping Pooling
Max Poolingを取る時に各unitを今までは「重複しない」ようにしていましたが、「少しかぶる」ようにすると過学習がおきにくくなり精度が向上したとのことです。
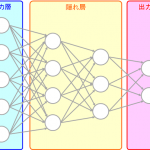
全体構造
構造になっており図示したものが以下になります。
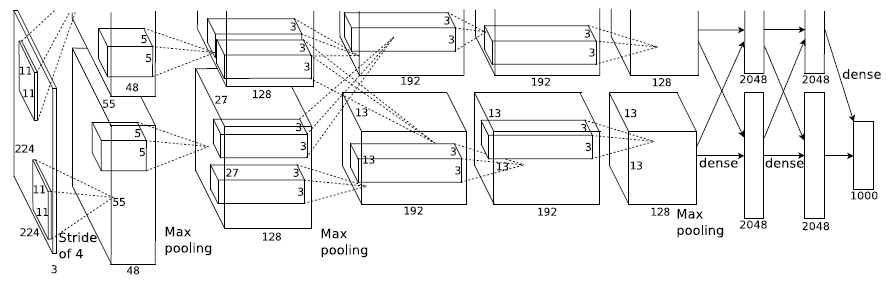
(出典:論文P.5 Figure 2)
5つの畳み込み層(第1~5層)と3つの全結合層があり各層の構造は以下になります。
- 第1層: [math]224\times 224 \times 3[/math]の画像を[math]11\times 11 \times 3[/math]の96個のkernelに変換
- 第2層: LRN & poolingした結果を[math]5\times 5 \times 48[/math]の256個のkernelに変換
- 第3層: LRN & poolingした結果を[math]3\times 3 \times 256[/math]の384個のkernelに変換
- 第4層: [math]3\times 3 \times 192[/math]の384個のkernelに変換
- 第5層: [math]3\times 3 \times 192[/math]の256個のkernelに変換
- 2つの全結合層: 4096個のニューロン
- 出力層: 1000個のsoft-maxニューロン
過学習の抑制
AlexNetは6000万個のパラメータを持つため過学習を避けるための工夫が必須です。
Data augmentation(データ拡張)
認識対象物が左右に反転したり、一部分が見切れていても人間は認識できることから学習画像を認識結果が変わらない程度に加工しデータを増やすことをdata augmentationと呼びます。
- Random crop: [math]256\times 256[/math]の画像から[math]224\times 224[/math]の画像をランダムに切り出し
- 水平反転
- RGBチャネル強度をランダムに変化
画像の変換処理は別の画像をGPUで学習中している間にCPUで行うため全体の計算時間への影響はほとんどないそうです。
Dropout
ニューロンの重みを強制的に0にする(dropoutと呼ぶ)ことで過学習を抑制し、よりロバストがモデルができることが経験的に知られています。AlexNetでは2つの全結合層でdropoutを使っており、dropoutなしではかなり過学習が起きたと報告しています。
学習の詳細
ハイパーパラメターの設定値など学習時の細かな話がまとめられています。
結果
ILSVRC2010, 2012の結果がまとめられており、人手で特徴量設計したモデルに圧勝しました。質的評価としていくつか判別がうまくいかなかった例が示されており、間違えても仕方がない(そもそも教師例の方が怪しい例もある)ものが多いことを確認しています。
Discussion
最後にDiscussionとして
- 純粋にDeepな畳み込みニューラルネットワークを教師あり学習するだけで大幅な精度向上を実現
- 中間層を除くと2%程度精度が悪化するのでdeepなことは本質的に精度に影響を与えている
とまとめられており究極的にはより曖昧な事象の認識や動画認識で使えるようにしたいとしています。
脚注
| ↑1 | データセットの詳細は「ImageNet(ILSVRC2012)データセット」を参照ください。 |
|---|

ピンバック: カーツワイルの「GNR」に「I」(情報科学・情報工学)が含まれていない理由を考える(4) | 人工知能ニュースメディア AINOW