確率変数[math]X[/math]のモーメント[math]E[X^n][/math]の算出でよく用いるモーメント母関数ですが、確率密度関数の導出でも活躍します。2016年に出題された問題を例に見てみましょう。
2016年(数理統計)の大問2(4)で
という問題が出題されました。数学的帰納法を使って示すこともできますが、
- [math]Y[/math]のモーメント母関数
- [math]g_n(y)[/math]のモーメント母関数
が一致することを示すことで[math]Y[/math]の確率密度関数が[math]g_n(y)[/math]になることを示せます。その根拠となるのが以下の定理です。
つまりモーメント母関数が一致することを示すことで確率密度関数の一致を示せます。図示すると以下の関係になります。
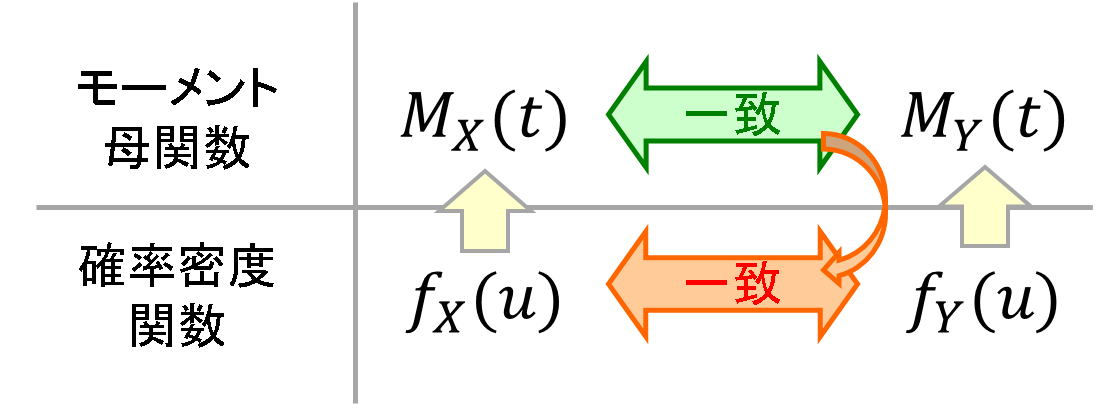
この定理を使って過去問を解いてみましょう。
まず、指数分布のモーメント母関数を求めると
[math]M_{X_i}(t)=E[e^{tX_i}]=\dfrac{\lambda}{\lambda-t}[/math]
になります。これより、
[math]
\begin{eqnarray}
M_{Y}(t)&=&E[e^{t\sum_{i=1}^{n}X_i}]\\
&=&\prod_{i=1}^nE[e^{tX_i}] \\
&=&\left(\dfrac{\lambda}{\lambda-t}\right)^n
\end{eqnarray}
[/math]
になります。
次に[math]g_n(y)[/math]のモーメント母関数を求めます。
まず[math]g_1(y)[/math]は指数分布の確率密度関数に他ならないので[math]M_{g_1(y)}(t)=\dfrac{\lambda}{\lambda-t}[/math]です。
さらに部分積分を使うことで
[math]
M_{g_n(y)}(t)=\dfrac{\lambda}{\lambda-t}M_{g_{n-1}(y)}(t)
[/math]
なので
[math]
M_{g_n(y)}(t)=\left(\dfrac{\lambda}{\lambda-t}\right)^n
[/math]
が得られます。
以上より
[math]
M_Y(t)=M_{g_n(y)}(t)
[/math]
なので[math]Y[/math]の確率密度関数は[math]g_n(y)[/math]に一致することが示せました。