データ分析と聞くと機械学習アルゴリズムを使ったモデル構築に目がいきますが、
- どのアルゴリズムが使えそうか
- アルゴリズムに適した形にデータ整形
するには分析対象のデータの内容をきちんと理解しておくことが重要です。そこで、分析の第一歩として
- データ定義の確認
- データ内容の確認
- 欠損データの確認
をしていきます。
データ定義の確認
Titanicチュートリアルでは乗客ごとに性別などの情報が提供されています。チュートリアルのサイトでの定義を整理すると以下になります。
- PassengerId: 乗客を特定するID
- Survived: 生存(1)したか否(0)か。学習データのみ提供
- Pclass: チケットのクラス。1stクラス(1), 2ndクラス(2), 3rdクラス(3)の3種類
- Name: 乗客の名前
- Sex: 性別。男性(male)か女性(female)の2種類
- Age: 年齢。1才未満は小数で記載し、推定値の場合は”〇〇.5″才の形式で記載
- SibSp: Sibling and Spouseの略。同時に乗船した兄弟/夫婦の数
- Parch: Parent and childの略。同時に乗船した親/子供の数
- Ticket: チケット番号
- Fare: 運賃
- Cabin: 客室番号
- Embarked: 乗船港。Cherbourg(C), Queenstown(Q), Southampton(S)の3種類
SibSpとParchはぱっと理解しづらいので特徴量を生成する際には理解しやすい形に変換した方が良いかもしれません。
データ内容の確認
train.txtの中身をテキストエディタで見てみると
PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked 1,0,3,"Braund, Mr. Owen Harris",male,22,1,0,A/5 21171,7.25,,S 2,1,1,"Cumings, Mrs. John Bradley (Florence Briggs Thayer)",female,38,1,0,PC 17599,71.2833,C85,C 3,1,3,"Heikkinen, Miss. Laina",female,26,0,0,STON/O2. 3101282,7.925,,S
となっています。ここから
- 英数字、カンマなどで記述されておりASCII文字で扱えそう
- Name中に区切り文字(カンマ)が出ることがあるので””で囲われている
- 欠損値もある
ことがわかります。test.csvもSurvived列がない以外はtrain.txtと同様です。今回のデータはpandas.read_csv関数でそのまま読めそうです。
今回は問題になりませんがデータに日本語が含まれる場合、文字コードに気をつける必要があります。特に列名が日本語の場合、
- コーディング中に英語/日本語の切り替えが発生し非効率
- RやPythonのパッケージで変数名が日本語だとエラーになることがある
ため列名を英語に変えておくのがオススメです。なお、Rは列名にハイフン(-)やアンダースコア(_)があるとread.table関数で読んだ際にドット(.)に変換されるので列名には使わないでおきましょう。
では、Jupyter notebookを起動しpandasを使ってデータの中身を確認しましょう。
ここではhomeディレクトリ配下にtitanic_tutorialというディレクトリを作りdataフォルダに学習、評価用データを入れています。titanic_tutorialディレクトリ上で
(titanic) $ jupyter notebook
でJupyter notebookを起動します。notebook自体はGithubにアップしていますが、データの行数、列数をみると
- 学習データ: 891行12列
- 評価データ: 418行11列
と機械学習用データとしては少ない部類に入ります。学習、評価データが少ないことも意識して分析を設計する必要がありますね。
次に学習、評価データの先頭10行を確認すると
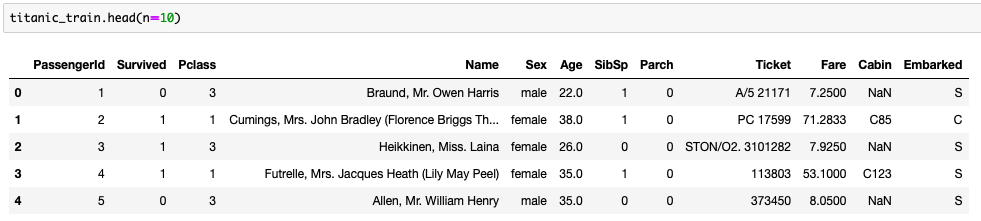
- Pclass, Sex, Age, SibSp, Parchなどは数値/カテゴリデータで扱いやすい
- Nameはテキストデータでそのままでは使いづらい
- Ticketもバリエーションが多く加工が必要
- Cabinは欠損が多いのとバリエーションが多く加工が必要
ということがわかります。続いて欠損値について確認していきましょう。
欠損データの確認
多くの機械学習のアルゴリズムは欠損値をそのまま扱うことができません。そのため欠損値の有無、割合をみて
- 欠損値を平均値などで補完したり、欠損値フラグ化する
- 欠損値があるサンプルを削除する
- 欠損値がある特徴量を削除する
といった方針を決める必要があります。今回の学習データで欠損値を確認すると
- Age: 177 (19.9%)
- Cabin: 687 (77.1%)
- Embarked: 2 (0.2%)
の3つの特徴量で欠損があり、評価データでは
- Age: 86 (20.6%)
- Fare: 1 (0.2%)
- Cabin: 327(78.3%)
で欠損が生じています。
Embarked, Fareは欠損がそれぞれ2件, 1件と少ないので個別に補完すれば良さそうですが、年齢は2割、Cabinは8割近く欠損しておりどう対処するか検討が必要ですね。
データ確認のまとめ
データ確認の結果を踏まえ、今後の分析で留意すべき点をまとめておきましょう。
- Ageは推測された値も含まれている。(年齢が「〇〇.5」になっているデータ)
- SibSp, Parchは分かりやすい形に変換することも検討
- 学習データ891件、評価データ418件と多くない
- Name, Ticket, Cabinはそのままは使いづらく加工が必要
- Ageでは2割, Cabinでは8割近くが欠損
- Embarked, Fareでも欠損あり
続いて各特徴量の基礎集計をしていきましょう。