数値データを適当な境界で区切りカテゴリデータ化することをビン分割(binning)と呼びます。例えば「年齢」をざっくり「年代」としてみることで傾向が捉えやすくなるなど機械学習ではよく行われる前処理の一つです。
pandasでは数値データをビン分割する方法として
- 指定した境界値でビン分割
- 含まれるデータ数が同一になるようにビン分割
が提供されておりここではその使い方を紹介します。なお、こちらで紹介したPythonスクリプトをGithubにアップしているのでそちらもご参照ください。
指定した境界値でビン分割
pandasには指定した境界値でビン分割を行うcut関数が用意されています。
pandas.cut(x, bins, labels)
主な引数して
- x: ビン分割を行う数値データ
- bins: ビン分割の境界値のリスト
- labels: ビンのラベル名のリスト(オプション)
を指定できます。
例えば年齢データとして平均40, 標準偏差10の正規乱数を1,000個生成し、このデータをビン分割してみます。ヒストグラムを確認すると
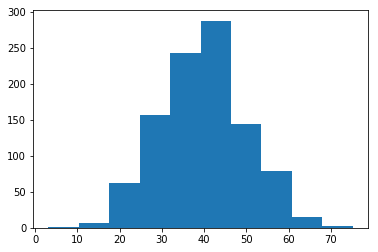
と当然のながら40付近に集中し、20未満/60以上は少ないことがわかります。そこで
- 20才未満
- 20〜60才までは10才刻み
- 60才以上
にカテゴリを分けてみましょう。
age_ctgr_list = [0, 20, 30, 40, 50, 60, 100] age_ctgr = pd.cut(age, bins=age_ctgr_list)
とするとビン分割されたデータが生成されます。念のためデータの中身を確認すると
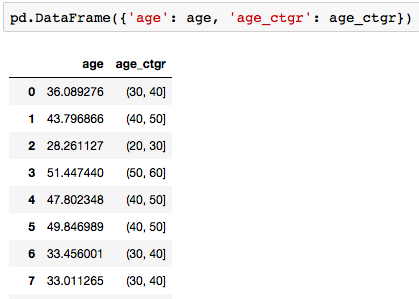
と確かに年齢データが指定したカテゴリに変換されていることがわかります。
さらにラベル名を指定したい場合は
age_ctgr_list = [0, 20, 30, 40, 50, 60, 100] age_ctgr_name = ['0-20', '20-30', '30-40', '40-50', '50-60', '60-'] age_ctgr = pd.cut(age, bins=age_ctgr_list, labels=age_ctgr_name)
とlabelsにラベル名のリストを指定します。
また、ラベル名ごと件数を集計しグラフにしたい場合は
plot_data = age_ctgr.value_counts().sort_index() plt.xticks(rotation=90) plt.bar(plot_data.index, plot_data)
でできます。
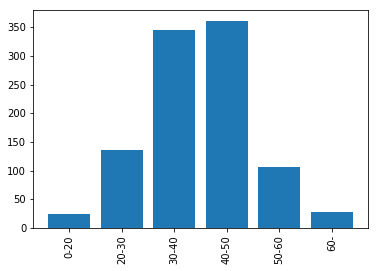
なお、ラベル名を付与しなかった場合はplot_data.indexがInterval型で「数値型や文字列型ではない」とエラーが出るので
plot_data = age_ctgr.value_counts().sort_index() x_labels = [str(ctgr) for ctgr in plot_data.index] plt.xticks(rotation=90) plt.bar(x_labels, plot_data)
と文字列型に変換して渡すと描画ができます。
含まれるデータ数が同一になるようにビン分割
qcut関数を使うと含まれるデータ数が同一になるようにビン分割ができます。データ分析では「とりあえず10分割して見てみるか…」と使うシーンはこちらの方が多いかもしれません。
pandas.qcut(x, q, labels, retbins, duplicates)
qcut関数では主な引数して
- x: ビン分割を行う数値データ
- q: ビン分割数
- labels: ビンのラベル名のリスト(オプション)
- retbins: ビンの境界値リストを返すか(オプション)
- duplicates: 境界値が重複した際にエラーを出すか(オプション)
を指定できます。
上の例と同じデータを10分割してます。
# 10分割 age_ctgr = pd.qcut(age, q=10)
分割した結果を確認すると

とCategoriesにあるように(6.952, 27.874]から(53.041, 71.967]まで10個のカテゴリが作成されています。
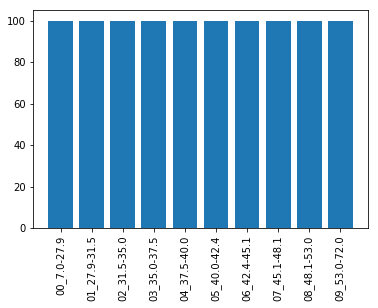
この結果をヒストグラム化してみると
# カテゴリごとに集計しplot plot_data = age_ctgr.value_counts().sort_index() x_labels = [str(ctgr) for ctgr in plot_data.index] plt.xticks(rotation=90) plt.bar(x_labels, plot_data)
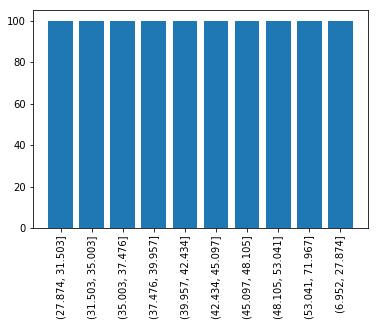
と確かに10個のカテゴリが生成されそれぞれのデータ数がほぼ同数になっています。
ただよく見ると文字列順にソートされているので(6.952, 27.874]のカテゴリが一番右に来ており数値順になっていないのが気になります。そこで
- 一度、ビン分割をして境界値のリストを取得
- 数値順の連番を振ったラベル名リストを作成
- ラベル名を指定してビン分割
としてヒストグラムを描画します。
# カテゴリごとに集計しラベルが昇順になるようにplot
age_ctgr, bin_def = pd.qcut(age, q=10, retbins=True)
age_ctgr_name = ['{:02}_{:.1f}-{:.1f}'.format(i, bin_def[i], bin_def[i+1]) for i in range(len(bin_def)-1)]
age_ctgr = pd.qcut(age, q=10, labels=age_ctgr_name)
plot_data = age_ctgr.value_counts().sort_index()
x_labels = [str(ctgr) for ctgr in plot_data.index]
plt.xticks(rotation=90)
plt.bar(x_labels, plot_data)
なお、qcut関数を使用した際にビン数が多いと境界値が重複してしまいエラーになることがあります。その場合は
pd.qcut(age, q=100, duplicates='drop')
とduplicatesオプションに’drop’を指定するとエラーを回避できます。


ピンバック: Pythonで株価のテクニカル指標をチェックする | 無次元日記