李世乭九段、柯潔九段に勝利したアルファ碁(AlphaGo)を開発したDeep Mind社が
人間の棋譜を一切使わず「自己学習」したAlphaGo Zeroが従来のAlphaGoに圧勝
したという衝撃的な論文”Mastering the game of Go without human knowledge”をNatureで発表[1]論文はDeep Mind社のブログ記事の”View Publication”から見ることができます。しました。
論文によると李世乭九段と対戦したAlphaGoから大きく3つ進化しています。
- 指し手の評価および局面評価を行うDeep Neural Network(DNN)を統合し、ResNet(Residual Network)ベースの構造に一新
- 評価精度向上に合わせ「読み」を行うモンテカルロ木探索(Monte Carlo Tree Search, MCTS)でplayoutせず局面評価値をそのまま使用
- 人間の棋譜データを一切使わず自己対戦の棋譜のみで学習
特に3が注目されていますが、いずれも画期的な進化でそれぞれ解説していきます。
AlphaGoの進化
論文ではAlphaGoの進化について触れられており5つのバージョン[2]論文中ではZero(short)とZeroは分けられていませんが、評価を正確にするため本記事では分けて記載します。が登場します。
- Fan: 2015年に樊麾二段と対戦したバージョン
- Lee: 2016年に李世乭九段と対戦したバージョン
- Master: トッププロ相手に60連勝し、2017年に柯潔九段と対戦したバージョン
- Zero(short): 自己対戦の棋譜のみ利用。検証用に3日間学習したバージョン
- Zero: Zero(short)のDNNを深層化し40日間かけて学習したバージョン
論文P.7に各バージョンの違いがあり主な変更をまとめると下図になります。
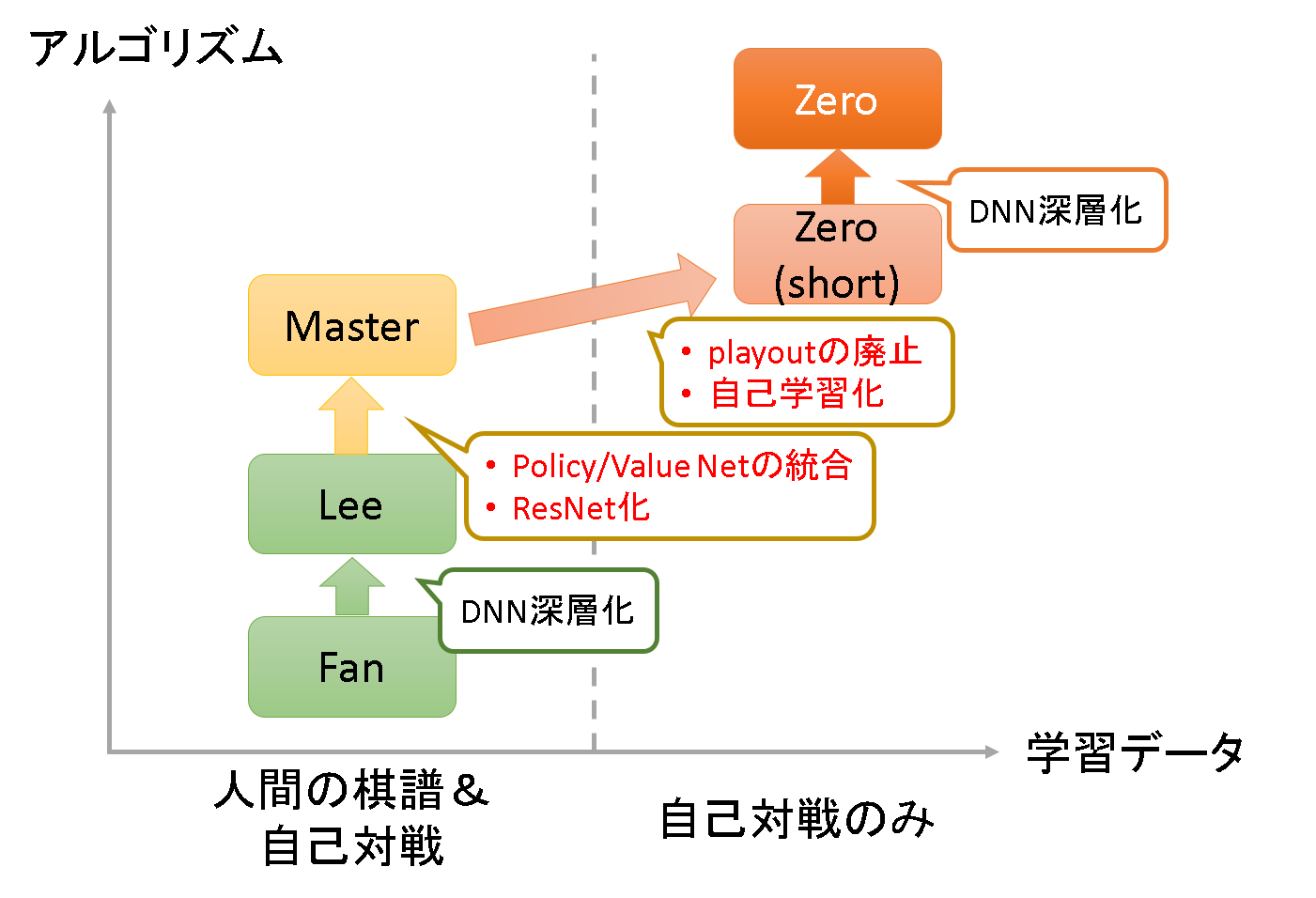
大きな違いは
- Master: 指し手評価(Policy network), 局面評価(Value network)を統合。また、DNNをCNN(Convolution Neural Network)ベースからResNetベースに変更
- Zero(short): MCTSでのplayoutの廃止、自己学習化
だと思います。まずはAlphaGo Masterで導入されたDNN構造の改良を見てみます。
DNN構造の改良
AlphaGo Leeではある局面で各指し手が打たれる確率[math]\mathbf{p}[/math]と、局面の評価値[math]v[/math]をそれぞれ別のDNNで学習して求めていました。AlphaGo Masterからは指し手の評価と局面の評価値[math](\mathbf{p}, v)[/math]をまとめて評価するDNNを用いています。
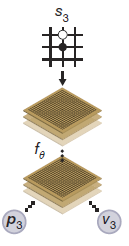
(出典:論文P.2 Figure 1から抜粋)
さらにDNNの構造をCNNベースからResNetベースに変更し、深層化しやすくしています。Policy/Value networkの統合、ResNet化でそれぞれEloレーティングが600程度向上[3]勝率でいうと97[math]\%[/math]程度の勝ち越しに相当します。し驚異的な改善につながりました。
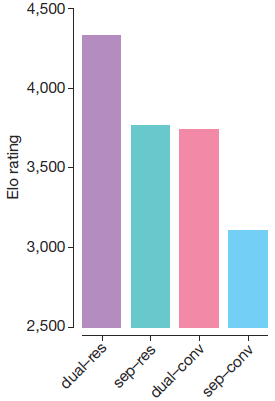
(出典:論文P.3 Figure 4から抜粋。dualが統合したDNN, resがResNetに対応)
モンテカルロ木探索の改良(playoutの廃止)
囲碁がコンピュータにとって難しいと言われていたのは局面の評価が難しいためでした。モンテカルロ木探索で
- playout[4]論文ではrolloutと呼ばれています。と呼ばれるランダム対局を繰り返す
- playoutの勝率を評価値として使う
ことで、局面の評価関数を作ることなく局面評価を実現し大きなブレイクスルーになりました。といっても、強い囲碁プログラムを作るにはplayoutの質を高める必要があり開発者達はplayout改良に血のにじむような努力をしていました。
しかし、AlphaGo Zero(short)ではplayoutをせず局面評価値[math]v[/math]をそのまま使います。
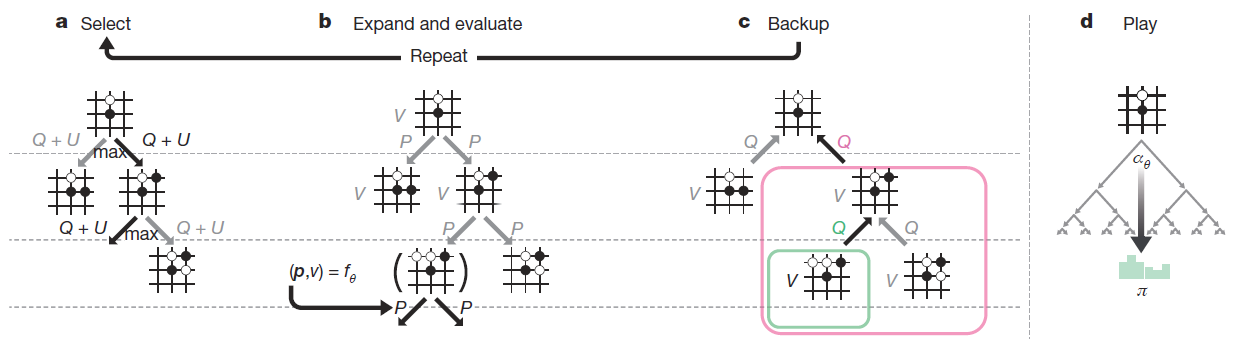
(出典:論文P.2 Figure 2から抜粋)
playout廃止の効果は論文中に示されていませんが、困難と思われた囲碁の局面評価もDNNで高精度な評価関数を作成可能で、もはやplayoutは必要ないことになり、コンピュータ囲碁界にとっては大きな衝撃だと思います。
自己学習
AlphaGo MasterまではDNNを学習する際に
- ある程度強くなるまでは人間の棋譜を利用
- 強くなってからは自己対戦の棋譜を利用
と人間の棋譜を利用していました。しかし、AlphaGo Zeroでは
- 初期値はランダムな値を設定
- 直近50万局からランダムに局面を選ぶ
- 指し手/対局結果の推定誤差を減らすように学習
- 学習前/後のモデルを400局対戦させ勝率55%を超えたら学習後モデルに更新
- 自己対戦を25,000局行い、2に戻る
と完全に自己対戦のみで学習を行います。論文では人間の棋譜を使って学習したモデルと比較しており下図の青い線が自己対戦のみ、赤い線が人間の棋譜を使ったモデルになります。
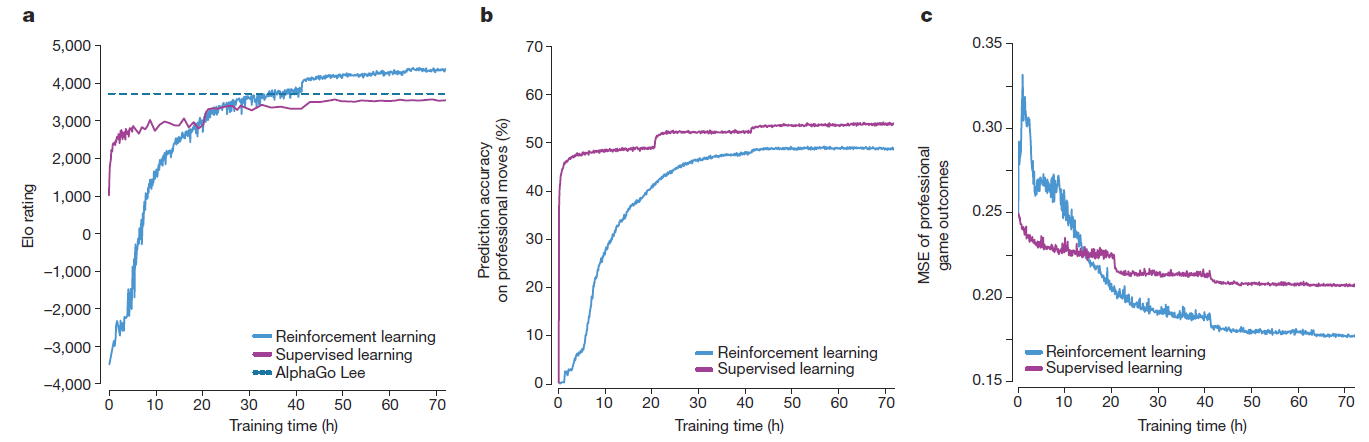
(出典:論文P.3 Figure 3から抜粋)
左から順に結果を見ると
- Eloレーティング: ある程度時間が経つと自己対戦版が上回る
- 人間の指し手との一致率:人間の棋譜を使ったモデルの方が高い
- 対局結果の推定誤差: ある程度時間が経つと自己対戦版の方が良い
となります。人間の棋譜を使うことで短時間でそれなりに良いモデルを作ったり人間の指し手を当てるには良いですが、強い囲碁プレイヤーを作るという観点では
人間の知識・経験はむしろ足かせで、ゼロから学習した方が囲碁の真理に近づける
とも取れる結果を示しています。まさにAlphaGo Zeroの名の通りゼロから自己学習し人知を超越した存在になった瞬間だと思います。実際、AlphaGo Zero(short)は学習の中で定石を発見した上でさらにその進化系とも取れる変化を見つけることに成功しています。また、AlphaGo Leeとの対戦でなんと100勝0敗と全勝を収めます。
AlphaGo Zeroの実力
AlphaGo Zero(short)での成功を受けDNNを深層化し、40日間もの自己学習を行ったのがAlphaGo Zeroです。AlphaGo Leeから驚異的な進化を遂げたAlphaGo Masterとの対戦でも89勝11敗と大きく勝ち越し、さらなる進化を証明しました。
AlphaGo Fan, Lee, Master, Zeroに加え幾つかの囲碁プログラム間を対戦させた結果が最後にまとめらており
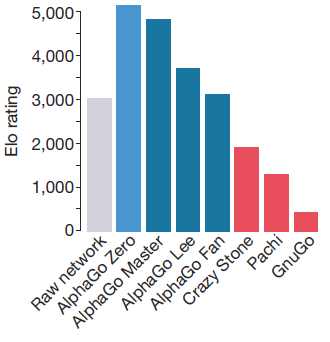
Masterで頭一つ抜け出し、Zeroでさらにそれを超えていった様子が見てとれます。
AlphaGo Masterの登場で人間より強い囲碁プログラムを作るという目標が達成され、今回のAlphaGo Zeroで自己学習のみで最強の囲碁プログラムを作るという目標も達成されました。もうコンピュータ囲碁で新たな目標を見つけることが難しくなってきたと思えますが今後、さらに新たな進化を見せてくれるのか興味深いところです。