さぁここから年齢、性別などの特徴量と生存率の関係を見ていきます。基本的には
- 特徴量の変化によって生存率に差がでるか?
- 特徴量の変化に対して生存率が上下したり非単調な変化をしていないか?
を確認します。特徴量生成の重要ポイントの1つが特徴量と目的変数の単調性[1]特徴量の増加に伴い目的変数が増加/減少し続けることを単調性と言います。で
- 回帰系のアルゴリズムは特徴量の変化に対する目的変数の単調性を仮定
- 木系のアルゴリズムも単調性があると学習が効率的
のため、非単調な変化がある場合はフラグ化、カテゴリ化などの変換を検討します。
また、「コンペで差をつける」…だけでなく、より良い「知見獲得」のためには
この特徴量と生存率との関係はきっとこうだろう
と仮説を持ち、疑問があれば繰り返し検証することで理解を深めることも重要です。
それでは「子供と女性を優先して救助した」と言われるタイタニック号沈没事故ですが実データが何を語るのか見てみましょう。
チケットのクラス(PClass)
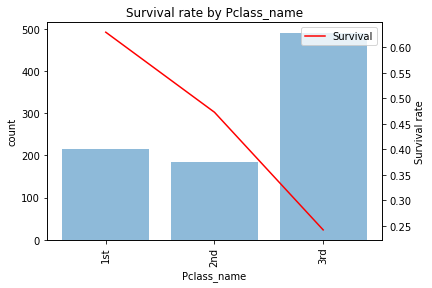
1st(63.0%), 2nd(47.3%), 3rd(24.2%)とクラスが上位ほど明確に生存率は上がります。
単調性があるのでPClassの値(=1〜3)をそのまま使っても良いですし、3値しかとらないので名義尺度(=1st or 2nd or 3rd)とみてダミー変数化するのも良いでしょう。
性別(Sex)
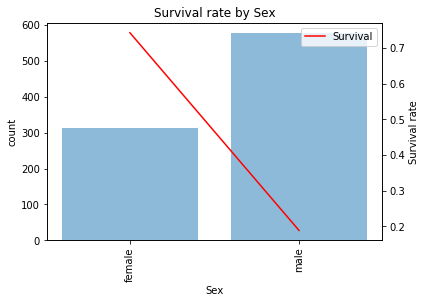
女性(74.2%)が男性(18.9%)を圧倒します。素直にダミー変数化して使いましょう。
年齢 (Age)
全体傾向
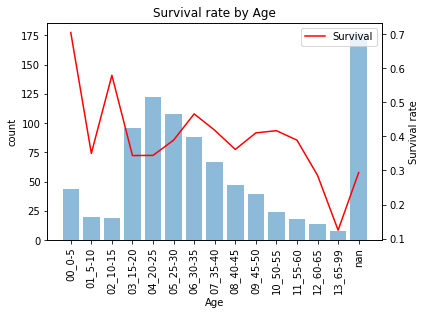
上図は5才刻みで見た生存率です。全体を見ていくと
- 0-5才(70.5%), 10-15才(57.9%)と高い生存率だが5-10才(35.0%)は平均並
- 15-60才は34-41%で平均(38.4%)とそれほど変わらない
- 60-65才(28.6%), 65才以上(12.5%)と低いので60才以上はまとめるのが良さそう
と概ね年齢が低いほど生存しやすいですが、0~15才では生存率が上下しており注意深くみる必要があります。
0〜15才の傾向
0〜5才で生存した人を見てみてると性別、チケットのクラス問わず生存しています。
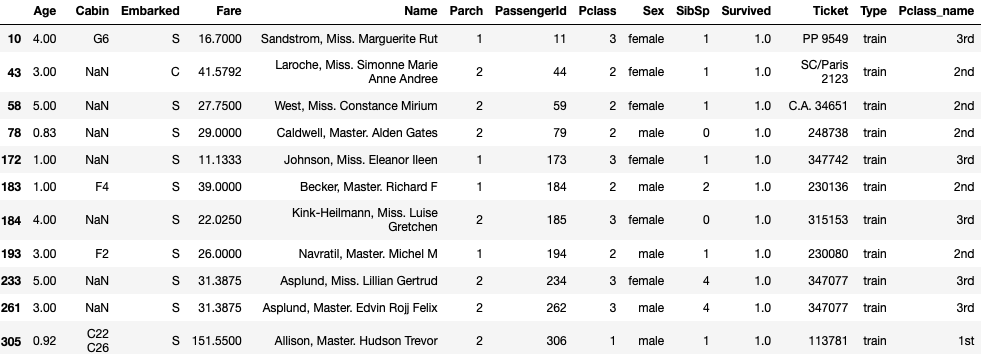
逆に死亡した人を見ると

大半が3rdクラスの乗客です。なお、ここでは表示サイズの関係で一部の結果しか表示していないので、ぜひこちらのコードを参考に結果全体を見てみてください。
チケットクラスの影響もありそうなので年齢別にクラスと生存率の関係を見ると(画像をクリックすると拡大表示されます)
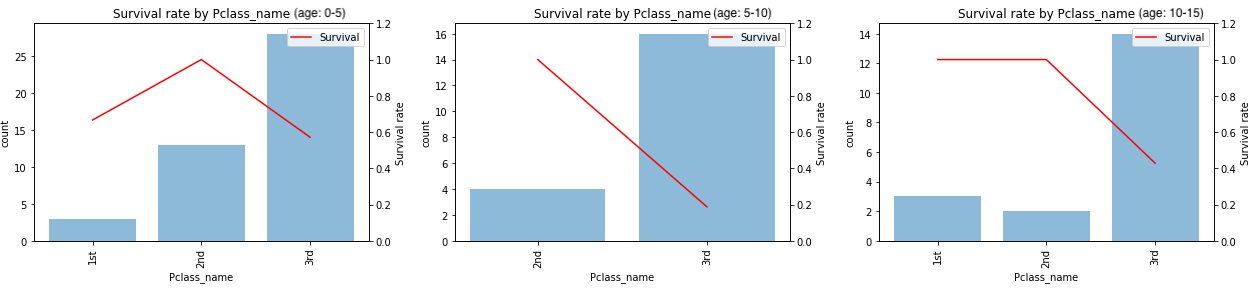
- 5才以下: クラスに関わらず生存率が高い
- 5〜10才: 2ndは4人全員が生存。3rdは16人中3人生存(18.8%)と低い
- 10〜15才: 2nd以上は5人全員が生存。3rdは14人中6人生存(42.9%)と高い
となっています。この結果から
- 5才以下の子供は優先的に救助
- 5〜15才は救助ボートにたどり着ければ優先して救助
- 1st, 2nd: 客室から救助ボートまで年齢に関係なくたどり着けた
- 3rd: 10才以上でないと客室から救助ボートまでたどり着くのは難しかった
と推察できます。5〜15才はクラスとの交互作用も考慮した方が良さそうです。
欠損値/推定値の傾向
データ確認編でみた通り年齢は20%程度欠損しており、欠損したデータでの生存率は29.4%と全体平均(38.4%)より10%近く低いです。
さらに年齢は推定値(「〇〇.5」才となっているデータ)もあり推定されたデータでは18人中1人のみ生存(5.6%)とほぼ死亡していることがわかります。

欠損、推定が生存予測に有用であることを示唆する一方、因果としては
乗客が死亡したため年齢が欠損 or 推定されている
と考えるのが自然です。
結果(目的変数)から導かれる情報が説明変数に入ってしまうことを「リーケージ」と呼び機械学習の厄介な問題の一つです。多くの場合、リーケージした情報が強烈に寄与しモデル精度は大きく向上しますが、「結果で結果を予測する」ことになり分析目的に照らし利用の妥当性を判断する必要があります。
例えば
- 事故の要因分析: 「年齢の欠損、推定が要因」と因果が逆転した結論を導出
- これから豪華客船に乗る人の生存予測: 「事故後の生存に依存した情報」を要求
することになりリーケージした情報は使えません。
今回はタイタニック号事故を題材に「一部のデータから残りを精度よく推定すること」が目的なので使っても良いと思いますが、リーケージを見つけた際には分析目的に立ち返って使うべきかを判断し、使わない勇気も必要です[2] … Continue reading。
クロス集計(前半)のまとめ
少し長くなったのでいったんまとめましょう。
- チケットクラス: 上位ほど生存率が高い。順序尺度として使っても名義尺度としてダミー変数化しても良さそう
- 性別: 女性が圧倒的に生存率が高い。ダミー変数化して使う
- 年齢
- 0〜15才: 「5才以下」「5〜15才(2nd以上)」「5〜10才(3rd)」「10〜15才(3rd)」と分けるのが良さそう
- 15才〜: 「15〜60才」「60才以上」に分けるのが良さそう
- 欠損値フラグ、推定値フラグを作るのが良さそう
クロス集計の後半では一緒に乗船した人数(SibSp, Parch)、運賃、乗船港について見てみます。