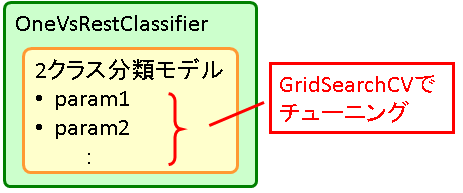
Pythonの機械学習ライブラリscikit-learnには2クラス分類モデルを複数用いて多クラス分類を行うOneVsRestClassifierが用意されています。
また、パラメタチューニングの仕組みとしてGridSearchCVが提供されていますが、そのまま使うとOneVsRestClassifierのパラメタしか動かせません。ここではOneVsRestClassifier内部で使われる2クラス分類モデルをGridSearchCVでチューニングする方法を紹介します。
実行例としてDigitsデータセットを題材にチューニングをしてみます。なお、PythonスクリプトをGitHub上にあげているのでそちらもご参照ください。
多クラス分類モデルOneVsRestClassifier
[math]K[/math]分類問題に対するOneVsRestClassifierは各ラベルに対し2クラス分類モデルを使い
「そのラベル」か「それ以外のラベル」か
を判定し最も該当しそうなクラスを返す分類モデルを構築します。
使い方は2クラス分類モデルをestimatorとして与えます。例えばSVCを使う場合は
from sklearn.svm import SVC from sklearn.multiclass import OneVsRestClassifier classifier = OneVsRestClassifier(estimator = SVC())
とするとSVCを用いた多クラス分類モデルが作れます。
GridSearchCVによるチューニング
こちらの記事で紹介したようにGridSearchCVを使うと与えたパラメタの全組合せについてCross Validationで評価し最も良いパラメタを探してくれます。
しかし、GridSearchCVをそのまま使うとOneVsRestClassifierのパラメタしか動かせず、内部で使っている2クラス分類モデルのパラメタが動かせません。実はGridSearchCVに渡すパラメタ名を
estimator__2クラス分類モデルのパラメタ名
とすると2クラス分類モデルのパラメタを動かすことができます。
例えば、SVCにはC, gammaという2つのパラメタがあるので
classifier = OneVsRestClassifier(SVC())
parameters = {
'estimator__C': np.logspace(-4, 4, 5),
'estimator__gamma': np.logspace(-4, 4, 5)
}
model_tuning = GridSearchCV(
estimator = classifier,
param_grid = parameters,
)
model_tuning.fit(X_train, y_train)
とするとSVCのパラメタC, gammaの組合せから最も良いパラメタを探してくれます。
実行例
データ/結果の可視化を含めたPythonコードをGitHub上にあげているのでそちらも合わせてご参照ください。
Digitsデータセット
scikit-learnには分類用のデータセットとして数字の手書き文字データが用意されており8×8ピクセルを一列に並べたサンプル1,797個が格納されています。Digitsデータを読み込んで学習/評価用データに分割しておきます。
from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split # Digits datasetのロード digits = load_digits() X = digits.data y = digits.target # 学習データと評価データに分割(分割比率8:2) (X_train, X_test, y_train, y_test) = train_test_split(X, y, test_size=0.2, random_state=0)
デフォルトパラメタでの予測
まずベース値としてデフォルトパラメタ[1]今回用いたscikit-learn v0.19.1ではC=1.0, gamma=1/1797で予測した時の精度を求めてみましょう。
# デフォルトパラメタ estimator = SVC() classifier = OneVsRestClassifier(estimator = estimator) classifier.fit(X_train, y_train)
精度は0.683で混同行列[2]行が正解ラベル、列が予測ラベルに対応し0-9の順に並んでいます。を求めると
Confusion matrix: [[26 0 0 1 0 0 0 0 0 0] [ 0 28 0 7 0 0 0 0 0 0] [ 0 0 22 14 0 0 0 0 0 0] [ 0 0 0 29 0 0 0 0 0 0] [ 0 0 0 3 27 0 0 0 0 0] [ 0 0 0 21 0 19 0 0 0 0] [ 0 0 0 3 0 0 41 0 0 0] [ 0 0 0 17 0 0 0 22 0 0] [ 0 0 0 32 0 0 0 0 7 0] [ 0 0 0 16 0 0 0 0 0 25]]
と迷ったら「3」と答えるモデルになっておりうまくモデルができているようには見えませんね。
SVCのチューニング
GridSearchCVの記事でも触れた通り「全パラメタの組合せ」[math]\times[/math]「CrossValidationの分割数」回のモデル構築/評価が行われ計算時間がかかるので最初は粗めにパラメタを刻むのが定石です。
まずはパラメタC, gammaともに[math]10^{-4}, 10^{-2}, 10^{0}, 10^2, 10^4[/math]とざくっと刻んでみます。
model = OneVsRestClassifier(SVC())
C_params = np.logspace(-4, 4, 5)
gamma_params = np.logspace(-4, 4, 5)
parameters = {
'estimator__C': C_params,
'estimator__gamma': gamma_params
}
model_tuning = GridSearchCV(
estimator = model,
param_grid = parameters,
n_jobs = -1,
verbose = 3
)
model_tuning.fit(X_train, y_train)
パラメタの範囲が妥当かを見るために横軸にgammaにとりCの値ごとに精度の折れ線グラフをplotしてみると
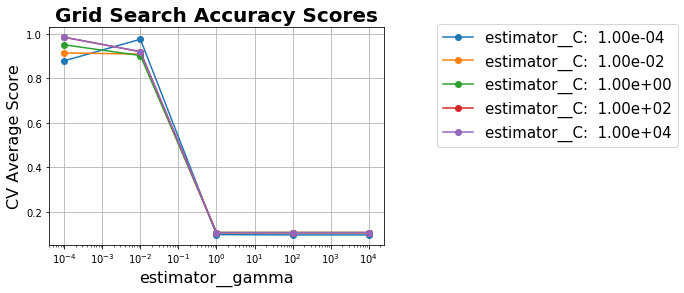
となっており
- gammaは[math]10^{-2}以下が良い[/math]
- Cはgammaと比べると精度への影響は少ない
ことがわかります。このチューニングだけで精度は0.983まで上がり混同行列も
Confusion matrix: [[27 0 0 0 0 0 0 0 0 0] [ 0 34 0 0 0 0 0 0 1 0] [ 0 0 36 0 0 0 0 0 0 0] [ 0 0 0 29 0 0 0 0 0 0] [ 0 0 0 0 30 0 0 0 0 0] [ 0 0 0 0 0 39 0 0 0 1] [ 0 1 0 0 0 0 43 0 0 0] [ 0 0 0 0 0 0 0 39 0 0] [ 0 1 0 0 0 0 0 0 38 0] [ 0 0 0 0 0 1 0 0 1 39]]
と対角線に数字が集まっておりうまくモデルができていることがわかります。
GitHub上のコードではC, gammaを
C_params = np.logspace(2, 5, 4) gamma_params = np.logspace(-5, -2, 4)
と精度が良さそうな範囲でさらに細かく刻むことで精度0.992まで向上しています。




こちらのコード参考させていただきました。
GridSearchCVのfigureを保存したくて、plt.figureのあとplt.savefigを使って見ましたところ、レジェンドの部分いつも切れてしまいます。
何か良い方法ご存知でしょうか?
お手数お掛け致します。
よろしくお願いいたします。
Rebeccaさま
plt.savefig(‘plot.png’, bbox_inches=’tight’)
とすると凡例部を含めて保存されるのではと思います。
教えていただきありがとうございます。
pythonもMachine Learningも初心者なので、大変助かりました。
またいろいろ参考させてください。