機械学習は「アルゴリズムの進化」と「データセットの進化」の両輪が揃って初めて進化すると言われています。ここではDeep Learning躍進の一翼を担った「大規模かつ良質なデータセット」の代名詞である
- ImageNetデータセット
- ILSVRC2012データセット
を紹介します。
ImageNetデータセット
![]()
ImageNetは
- 1,400万枚を超える画像
- 画像に写っている物体名(クラス名)を付与
- 物体名(クラス名)は2万種類以上
を収録したデータベースです。ImageNet登場以前にも画像認識用データセットとして
- MNIST: 手書き数字(0-9)画像を数十万枚収録
- CIFAR-10: 飛行機、鳥など10クラスの画像を数万枚収録
がありましたがImageNetはクラス/画像数共に桁違いに大きいデータセットです。
また、クラス名はWordNetという概念辞書の用語を使っておりWordNetを参照することで上位語、下位語(「ダルメシアン」の上位語は「犬」など)なども考慮できるのも大きな特徴だと思います。
画像の確認方法
ImageNetのサイトに行き検索ボックスにキーワードを入力するか、Exploreという項目をクリックすると階層的に調べることができます。例えば「Java sparrow」(文鳥)と入力して検索すると
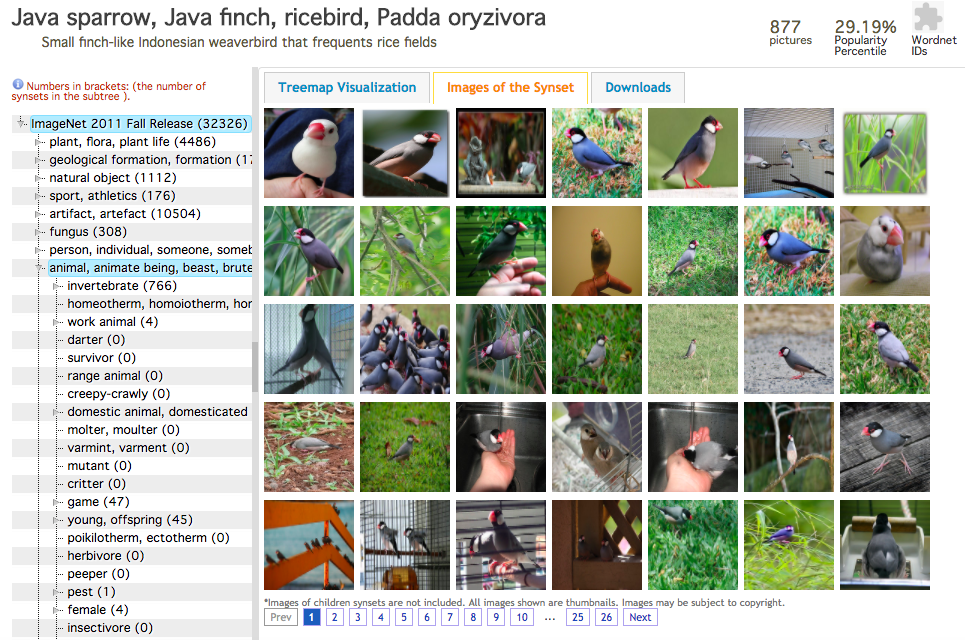
とずらっと文鳥画像が表示されます。
入手方法
ImageNetでは画像をWEBクローリングで収集しており著作権の関係から
- 画像のURL
- synsetと呼ばれる物体名(クラス名)
のリストのみ[1]研究・教育目的の場合は特定条件下でImageNetからダウンロード可能のようです。提供しています。
ImageNetのトップページから”Download” -> “Image URLs”を選ぶとダウンロードページに移動できます。最新版は”Fall 2011 Release”で圧縮ファイルで350MB, 解凍後で1.14GB程度のファイルになります。ファイルの中身は
$ head -n 3 fall11_urls.txt n00004475_6590 http://farm4.static.flickr.com/3175/2737866473_7958dc8760.jpg n00004475_15899 http://farm4.static.flickr.com/3276/2875184020_9944005d0d.jpg n00004475_32312 http://farm3.static.flickr.com/2531/4094333885_e8462a8338.jpg
と
- ImageID: “WordNetID_数字”の形式で記録
- 画像URL
がスペース区切りで記録されています。ImageNetの画像を研究・教育目的以外で利用するにはこのURLリストを使って自分でダウンロードする必要があります。
ILSVRC2012データセット
ImageNetのデータセットを題材とした画像認識のコンペティションILSVRC(ImageNet Large Scale Visual Recognition Challenge)が毎年開催されており2012年のコンペで使われたのがILSVRC2012データセットです。
クラス分類(classification)用のデータセットとして有名で「ImageNetデータで学習済み」と謳っている事前学習済モデルのほとんどはこのILSVRC2012データセットで学習したモデルだと思います。
ILSVRC2012データセットはImageNetの中から
- 物体名(クラス名): 1,000個
- 学習用データ: 120万枚
- 検証用データ: 5万枚
- 評価用データ: 10万枚
を抽出したデータセットです。
ILSVRC2012データセットの物体名(クラス名)
ILSVRC2012データセットに採用された物体名(クラス名)はILSVRC2012のページの「Browse the training images of the 1000 categories here.」から確認できます。
なお、各物体名の訳をGitHubにアップしているので日本語名の方がイメージしやすい方は参照ください。
各クラスの画像を収集し一つ一つ確認(「ILSVRC2012データセット クラス別画像」を参照ください)していくと
- 現実の環境、状況を撮影した写真がほとんど
- 動物(特に犬、猫、は虫類)が多い
- ただし、人間は含まれない
ことに気がつきます。実際、クラス名をWordNetIDに紐づけてWordNetの上位語を求め[2]WordNetの上位語の取得方法はこちらの記事を参照ください。第7階層の分類で見ると
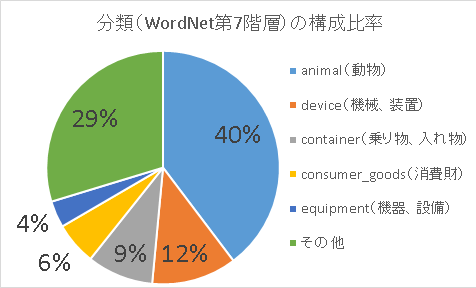
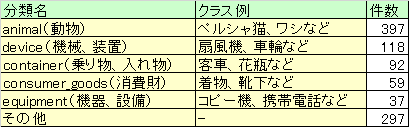
と
- 全体の約4割が「動物」
- 「動物」「機械、装置」で過半数を占める
と結構、偏ったラベル構成になっていることが分かります。
転移学習[3]転移学習についてはこちらの記事等をご参照ください。の文脈では「転移元のドメイン」(事前学習したデータの傾向)と「転移先のドメイン」(追加学習で使うデータの傾向)が近いかどうかが成否を分けるポイントとされILSVRC2012で事前学習したモデルが
- 自然環境を撮影したデータには強い
- マンガ、アニメ、レントゲン写真などには弱い
と言われるのもILSVRC2012データセットの偏りに起因するものと思われます。
認識精度
ILSVRC2012はHinton先生らがAlexNetをひっさげ圧倒的な性能で優勝した回としても知られ、その後もベンチマークとして精度検証が続いています。
通常はTop 5 Errorと呼ばれる「5つ解答し、そのいずれもハズレだった割合」が評価指標[4]複数の物体が同一写真に写ることがあり単一解答での評価はそぐわないためだと思います。として用いられます。有名モデルの認識精度は
- AlexNet: 15.3%
- VGG16: 7.3%
- GoogLeNet: 6.7%
- ResNet: 3.6%
となっています。ちなみに人間の認識精度は5.1%と言われていますがデータセットを実際にみると犬種などかなり細かな違いを識別する必要があり自分がやったらもっと誤差率は高くなる気がします。そう考えるとVGG16以降の10%以下の誤差率というのはもはや一般の人間を超えたレベルと言ってよいのではと思います。



>ImageNetは
>1,400万枚を超える画像
140万枚ですよ!
コメントありがとうございます。
ImageNetのサイト(http://image-net.org/explore)を見ると
“14,197,122 images”
とあるので(2018/06/11現在)、およそ1400万枚ありますね。
蛇足ですが、ImageNetからコンペ用に抽出したデータセット(ILSVRC2012データセット)は135万枚なのでおよそ140万枚になりますね。