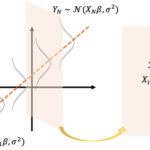
深層学習(Deep Learning)の登場により画像認識の性能が劇的に向上し、時には「人間の認識能力を超えた」とまで言われるようになりました。ただ、画像認識のタスクにはいくつか種類があり難易度が大きく異なります。ここでは画像認識のコンペで競われることの多い4つのタスク
- クラス分類(classification)
- 位置特定(localization)
- 物体検知(detection)
- セグメンテーション(segmentation)
の違いについて説明します。
クラス分類(classification)
クラス分類は画像に写っている物体が「dog」「airplane」「bird toy」など事前に定義されたラベルのどれが適切かを識別する問題です。

例えば上の例では「bird toy」を答える問題になります。
ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 2012というコンペで競われた
- ラベル数: 1,000
- 学習用画像: 120万枚
- 検証用画像: 5万枚
- 評価用画像: 10万枚
データセット[1]データセットの詳細は「ImageNet(ILSVRC2012)データセット」を参照ください。が有名で、今でもアルゴリズムの評価によく使われています。人間のtop5エラー率[2]5つのラベルを解答し、正解がそのいずれにも入らない割合が[math]5.1\%[/math]程度なのに対し、2015年に登場したResNetは[math]3.57\%[/math]を達成し
クラス分類においては人間の認識精度を上回った
という金字塔を打ち立てました。
位置特定(localization)
位置特定はクラス分類に加え、そのラベルの物体がどこにあるのかを矩形位置で特定する問題です。例えば先ほどの例では「bird toy」と答えるだけではなく

と矩形位置もあわせて答える必要があります。
物体検知(detection)
位置特定は1つの画像につき
1つの物体のラベルとその矩形位置
を答える問題でしたが、物体検知は画像に写っている
すべての物体のラベルとその矩形位置
を答える問題になります。同じ画像例で言うと

と答える必要がある問題になります。
クラス分類や位置特定で用いる画像は1画像に1つ物体のみ写っていることが前提になりいかもに「タスク用に用意した画像」感が否めませんが、物体検知だと複数の物体が写り込んだ画像を対象にするのでぐっと応用が広がるタスクになります[3] … Continue reading。
セグメンテーション(segmentation)
物体検知では物体の位置を矩形位置で特定していましたが、セグメンテーションではピクセル単位で特定する問題になります。再度、例をあげると

と輪郭を囲った領域を解答する必要があります。こちらも自動車の自動運転などでは周囲の状況を当然、矩形ではなく境界を正しく認識しないと安全な走行はできないので、いかに効率的かつ精度良く認識できるか活発に研究が行われています。
脚注
| ↑1 | データセットの詳細は「ImageNet(ILSVRC2012)データセット」を参照ください。 |
|---|---|
| ↑2 | 5つのラベルを解答し、正解がそのいずれにも入らない割合 |
| ↑3 | 物体検知アルゴリズムでは内部的にクラス分類/位置特定のアルゴリズムが使われており「クラス分類」「位置特定」の重要性が低いということではありません。 |