概要
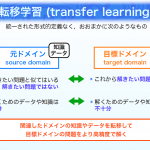
東大 中山先生による画像認識分野における畳み込みニューラルネットワーク(CNN)&fine-tuningによる転移学習の解説論文です。先生のHPに論文のPDFおよびパワーポイント資料がアップされています。
論文は画像認識におけるCNNをはじめとした深層学習の歴史も非常に分かりやすくまとめられており、CNNを用いた転移学習について日本語で読める貴重な文献です。パワーポイント資料はイメージが多用されていててさらに分かりやすいのと、論文に載っていない内容もスライドに入っているのでオススメです。
画像認識における歴史と発展
深層学習が一般物体認識で大成功を収めた理由として以下の3点が挙げられています。
- CNNの構造が一般物体認識のタスクに非常にうまくはまった
- ImageNetなど良質な大規模教師付データセットの整備
- GPGPUによる計算能力の大幅な向上
特にImageNetのデータ[1]ImageNetを使ったデータセットILSVRC2012の詳細はこちらを参照ください。を題材としたコンペで2012年にトロント大Hintonらが2位に10%以上もの大差をつけて圧勝して一躍有名になりました。それからわずか2年程度で人間のエラー率と同等以上のレベルにまで性能が向上しています(人間のエラー率5.1%に対して2015年1位チームのエラー率は4.8%)。
今や人工知能ブームの立役者と言っていいディープニューラルネットワーク(狭い意味では画像認識におけるCNN)はいったいどういう原理で何を学習するモデルなのか?というかが話題になりますが、この論文では
直感的には,入力の解像度を少しずつ落としながら異なるスケールで隣接する特徴の共起をとり,識別に有効な情報を選択的に上層へ渡していくネットワークであると解釈できる.
と説明されています。なんとなく分かった気になりますが、まだまだDNNの構成法や学習方法の研究が猛スピードで進んでいるところを見るとまだまだ奥深そうです。
CNNを用いた転移学習
大量の良質の教師データを用意するのは非常に大変なのでImageNetなどで訓練したCNNがどこまで別のタスクに知識転移できるのかは気になるところです。
CNNの転移方法としては2つ紹介されています。
- Pre-trainedネットワーク: 学習済ネットワークを固定して特徴抽出器として利用
- Fine-tuning[2] … Continue reading: pre-trainedネットワークの識別層を対象タスクに取替え、その他部分は学習済みのパラメータを初期値として学習
Pre-trainedは手軽に利用できるのがメリットで、Fine-tuningはPre-trainedよりさらに精度を出しやすいと言われています。実際、Fine-tuningがPre-trainedやフルスクラッチ学習(移転先ドメインのデータのみで学習)と比べて格段に精度が向上したケースが紹介されています。
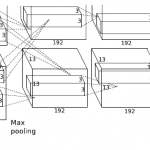
Pre-trainedの利用にあたってはCNNでは入力に近い層から識別層に近づくにつれて低次の視覚的特徴からデータセットに特化した意味的な特徴に構造化されることが知られているそうです。そのため
- 低すぎる層をとるとCNNの高い識別構造の恩恵を受けられない
- 高すぎる層をとると学習時のデータセットに特化してしまい転移学習の性能が下がってしまう
というトレードオフがあり経験的には「識別層の1つ2つ手前の全結合層」を用いることが多いそうです。
また、転移学習では
- Pre-trainedに用いるCNNの性能に大きく依存
- Pre-trainedで用いたタスクが移転先のタスクを内包していないと効果が薄い
ということも指摘されています。パワーポイント資料(P.38-39)では、移転先のタスクを含むタスクでpre-trainedさせる重要性が紹介されています。
論文の最後に触れられていますが
手法とデータは車の両輪の関係にあり,両者をバランス良く発展させることが,深層学習が次のブレークスルーを起こせるか否かの鍵であると考える.
にあるとおりだと思います。手法については我々でも少しお金をかければ最新の手法を試す環境を作ることができるのに対し、良質な教師データを大量に準備するのはハードルが非常に高いのでデータを制する者が今後の深層学習を制する者になりそうですね。