概要
Deep Learning躍進の一翼を担った「大規模かつ良質なデータセット」の代名詞である「ImageNet」が何を目的にどのように構築したのかを解説した論文です。ImageNetは1,000万枚以上の画像という「量」に注目が集まりがちですが論文では「質」も評価されており、その質の高さも特徴の一つだと思います。
また、アノテーション作業をクラウドソーシングする際の工夫点も述べられておりこれからアノテーションをする人にも参考になると思います。
論文はImageNetのPublicationからPDFをダウンロード可能です。あわせてLi Fei-Feiさんのプレゼン”ImageNet: crowdsourcing, benchmarking & other cool things”(PDF)を見るとどのように収集されたのかイメージしやすいと思います。
イントロダクション
まず「1. Introduction」のセクションではFlickrやYouTubeなどの普及を受けImageNet構築の目的が述べられています。
概念体系に基づいて収集、整理された大規模画像データセットは
- 洗練された画像検索
- 画像認識アルゴリズムの理解
- 画像認識アルゴリズムの学習データセットやベンチマーク
の重要なリソースになると信じている。
実際、ImageNetはWordNetという概念辞書を用いて画像のクラス名が設定されておりWordNetを参照して「上位語/下位語」などの概念の階層関係を利用することができるのもImageNetの特徴だと思います。
ImageNetの特徴
ImageNetの特徴として
- 規模: 5,247クラス、320万枚の画像[1]論文発表時の数字。2018年3月時点で21,841クラス、1,400万枚の画像が収集されています
- 階層性: クラス名がWordNetで定義されており概念間の階層性を考慮可能
- 正確さ: アノテーション精度が[math]99.7\%[/math]と高精度
- 多様性: 画角や物体位置など多様性に富む画像が含まれている
が挙げられています。どれだけDeep Learning技術が進化しようと学習データの精度が低いと意味がないのですが、ImageNetのアノテーション精度(各画像がクラス名に合致した画像かどうか)は[math]99.7\%[/math]と非常に高い精度ですね。
「多様性」については定量的な評価は難しいとしつつも
- 各クラスに含まれる画像の平均画像を作成
- 各クラスの画角や物体位置に特定のパターンがあれば平均画像にしてもぼんやりとその傾向が残り、多様性に富んでいればランダム画像に近づくはず
- 平均画像がランダム画像に近いほどロスレスJPEGで圧縮後のファイルサイズが大きくなるはず
という考えで平均画像のロスレスJPEGのファイルサイズで比較しています。

(出典:論文P.4 Figure 5を元に作成)
上の図ではCaltech101というデータセットとImageNetでのパンダの平均画像を比較しています。Caltech101のパンダ画像は平均画像でもうっすらパンダの形が分かる一方でImageNetの平均画像はよりぼんやりとした画像(=ランダム画像に近い)になっていることが分かります。
また、ImageNetと既存の画像データセット”Small image datasets”, “Tiny Image”, “ESP dataset”, “LabelMe and Lotus Hill datasets”と比較されています。いずれも「画像/クラス数」「クラスあたりの画像数」「画像の解像度」「無償で使えるか」など観点でImageNetに優位性があります。
ImageNetの構築
ImageNetは次の2つのステップで構築されています。
- 画像収集
- 画像のアノテーション
画像収集
ImageNetはWebクローリングで画像を収集しています。
- 1クラスあたり500〜1,000画像を集める
- 画像検索で検索ワードに合致した画像が表示される割合は[math]10\%[/math]程度なので1クラスあたり1万枚の候補画像を収集
- 検索ワードはWordNetの用語を利用
- より多くの画像を得るためにWordNetの上位語のキーワードも組み合わせ検索ワードを作成
- 中国語、スペイン語、ドイツ語、イタリア語にも翻訳して検索
該当のクラス名だけでなく、その上位語を使って検索ワードのバリエーションを増せるのはWordNetを使ったからこそできる芸当ですね。
画像のアノテーション
画像のアノテーションではクラスに対応する検索ワードで収集した候補画像が本当にそのクラスの画像かどうかを目視で確認します。
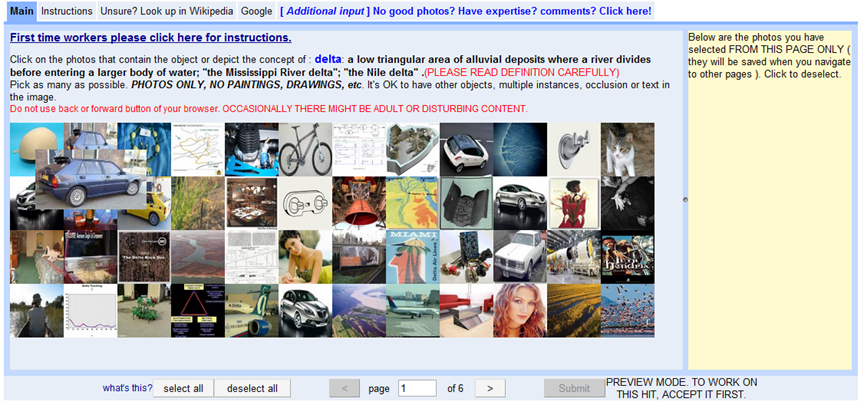
(出典:パワーポイント資料の”Basic User Interface”スライド)
上の図は実際のアノテーションツールの画面でクラス名の定義を踏まえずらっと表示された画像の中からクラス名に合致する画像を選択する仕組みになっています。画像に写っているものが1000クラスのうちのどれか?ではなく、画像に写っているものがある特定の物体か否かの2択にしているのが当然とはいえ、アノテーションを効率化するキーポイントだと思います。
とはいえ、Fei-Feiさんのプレゼン資料によると1画像の確認に0.5秒かかるそうで仮に1人でやると不眠不休でやったとしても19年かかる計算になります。そこでAmazon mechanical turk(AMT)というクラウドソーシングサービスを利用し人海戦術で大量画像のアノテーションを実施しています。クラスドソーシングする際の工夫として
- 「WordNetでの定義」「Wikipediaのリンク」を提示しクラス定義の理解を促進
- 定義の理解が正しいかアノテーション前にクイズを実施
- アノテーションが簡単なクラスもあれば難しいクラスもある。複数人のアノテーション結果から意見が分かれる画像は多くの人の結果を集め、意見が一致する画像は少ない人数で終えることでコストパフォーマンスを向上
が紹介されています。この仕組みで半年で300万枚の画像のアノテーションを実施できたとのことです。
ImageNetの活用例
「5. ImageNet Application」では3つのアプリケーションが報告されています。
- 画像解像度と物体認識精度の関係: 画像を[math]32\times 32[/math][2]TinyImage datasetと同じ画像サイズに縮小した画像とオリジナル画像とで精度を比較し精度が向上することを確認
- 階層関係を利用した集団学習: 画像があるクラスに含まれるかどうかを「そのクラスの下位語のクラスの学習器」を作り下位語の学習器の最大確率を使って判定することで精度向上を確認
- 物体の位置特定: あるカテゴリに含まれる画像を細かい矩形に分割し、カテゴリに所属する確率が最も高い矩形を選ぶことで物体の位置特定が可能
結論と今後の課題
今後の課題として2つ挙げられています。
- ImageNetの完成: 5万カテゴリ、5,000万画像のデータセットの構築
- ImageNetの活用: 学習データセット、ベンチマーク、人間の認知/認識を反映した新しいセマンティックの導入
ImageNetは2万カテゴリ、1400万枚の画像を有する巨大なデータセットとして知られていますが、この壮大な目標から見るとまだ半分にも到達していないのですね。活用についてはDeep Learningの躍進の一翼として大きな貢献を果たしており目的を達成できたと言えると思います。