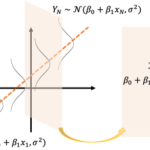
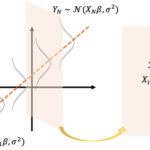
誤差項が独立同一な正規分布に従う場合、「単回帰係数が従う確率分布」の結果から予測区間(Prediction Interval)を構成することができます。
よく「信頼区間」と混同されるので違いに注意しながら説明していきます。
なお、PythonスクリプトをGitHub上にあげているのでそちらも参照し、記事の内容と実行結果を合わせて見ていただくと理解しやすいと思います。
また、重回帰モデルでも同様の結果を導出できます。関心のある方は
もご参照ください。
確率モデル
ここでは目的変数[math]Y_i[/math]と説明変数[math]x_i[/math]の間に
[math]
Y_i = \beta_0 + \beta_1 x_i + \varepsilon_i,\quad i=1,\dots,N
[/math]
の関係があり誤差項[math]\varepsilon_i[/math]は独立で同一の正規分布[math]\mathcal{N}(0, \sigma^2)[/math]に従うと仮定します。
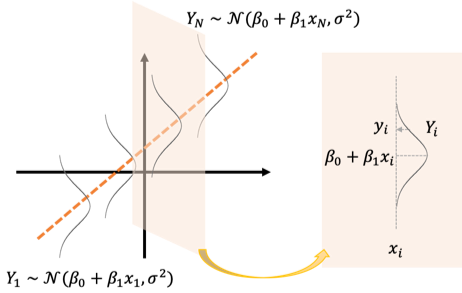
確率変数[math]Y_i[/math]の観測値を[math]y_i[/math]とします。確率モデルは何が確率変数で何が確定値なのかわかりにくいので改めてまとめると
- [math]x_i,\ y_i[/math]: 既知の確定値
- [math]\beta_0,\ \beta_1,\ \sigma^2[/math]: 未知の確定値
- [math]Y_i,\ \varepsilon_i[/math]: 確率変数
になります。
最小二乗推定量[math]\hat{\beta}_0, \hat{\beta}_1[/math]が従う確率分布
「単回帰係数が従う確率分布」の結果から最小二乗推定量[math]\hat{\beta}_0, \hat{\beta}_1[/math]は
- [math]\hat{\beta}_0[/math]: 平均[math]\beta_0[/math], 分散[math]\left(\dfrac{\bar{x^2}}{S_{xx}}\right)\sigma^2[/math]の正規分布
- [math]\hat{\beta}_1[/math]: 平均[math]\beta_1[/math], 分散[math]\dfrac{\sigma^2}{S_{xx}}[/math]の正規分布
に従います。また、分散[math]\sigma^2[/math]の不偏推定量[math]S^2=\frac{1}{N-2}\sum_{i=1}^N\left(Y_i – \hat{\beta}_0 – \hat{\beta}_1 x_i\right)^2[/math]に対して[math]\left(\hat{\beta}_0, \hat{\beta}_1\right)[/math]と[math]S^2[/math]は独立であり[math]\frac{(N-2)S^2}{\sigma^2}[/math]は自由度[math](N-2)[/math]の[math]\chi^2_{N-2}[/math]分布に従います。
予測区間と信頼区間の違い
ここからは信頼区間同様に説明変数を[math]x=x_0[/math]と任意に固定して考えます。信頼区間では
誤差項を含まない真の値: [math]\beta_0 + \beta_1 x_0[/math]
が考察の対象でしたが、予測区間では
誤差項を含む目的変数の値: [math]\beta_0 + \beta_1 x_0 + \varepsilon[/math]
が考察対象になります。つまり予測区間では「[math]x=x_0[/math]での観測値」がどの区間に入りやすいかを議論します。
目的変数[math]Y[/math]が従う確率分布
[math]x=x_0[/math]での目的変数[math]Y_0[/math]は
[math]
\begin{eqnarray}
Y_0 &=& \beta_0 + \beta_1 x_0 + \varepsilon \\
&\sim& \mathcal{N}(\beta_0 + \beta_1 x_0, \sigma^2)
\end{eqnarray}
[/math]
に従います。ただ、[math]\beta_0, \beta_1, \sigma^2[/math]は未知なので推定量で置き換えることを考えます。
目的変数[math]Y_0[/math]の推定量である[math]\hat{y}_0 = \hat{\beta}_0 + \hat{\beta}_1x_0[/math]との差
[math]
W = Y_0 – (\hat{\beta}_0 + \hat{\beta}_1x_0)
[/math]
を考えます。[math]Y_0, \hat{y}_0[/math]は正規分布に従うので[math]W[/math]も正規分布に従います。期待値を求めると
[math]
\begin{eqnarray}
E\left[W\right] &=&
E\left[Y_0\right] –
E\left[\hat{\beta}_0 + \hat{\beta}_1x_0\right] \\
&=& \beta_0 + \beta_1 x_0 – (\beta_0 + \beta_1 x_0) \\
&=& 0
\end{eqnarray}
[/math]
です。[math]x_0[/math]は学習データ[math]x_i[/math]に依存しないので[math]Y_0[/math]は[math]\hat{\beta}_0, \hat{\beta}_1[/math]とは独立になり分散は
[math]
\begin{eqnarray}
V\left[W\right] &=& V\left[Y_0\right] + V\left[\hat{\beta}_0 + \hat{\beta}_1x_0\right] \\
&=& \sigma^2 \left(1 + \dfrac{1}{N} + \dfrac{(x_0 – \bar{x})^2}{S_{xx}}\right)
\end{eqnarray}
[/math]
になります。ここで[math]\bar{x}=\frac{1}{N}\sum_{i=1}^N x_i[/math], [math]S_{xx} = \sum_{i=1}^N (x_i – \bar{x})^2[/math]です。
さらに[math]Y_0, \hat{\beta}_0, \hat{\beta}_1[/math]は[math]S^2[/math]と独立なので統計量[math]T[/math]は
[math]
\begin{eqnarray}
T &=& \dfrac{\frac{Y_0 – (\hat{\beta}_0+\hat{\beta}_1x_0)}{\sqrt{V\left[W\right]}}}{\sqrt{\frac{(N-2)S^2}{\sigma^2}\cdot \frac{1}{N-2}}} \\
&=& \dfrac{Y_0 – (\hat{\beta}_0+\hat{\beta}_1x_0)}{S\sqrt{1+\frac{1}{N} + \frac{(x_0 – \bar{x})^2}{S_{xx}}}}\sim t_{N-2}
\end{eqnarray}
[/math]
自由度[math]N-2[/math]の[math]t[/math]分布に従うことが分かります。この結果から予測区間を構成します。
単回帰モデルの予測区間
予測区間
統計量[math]T[/math]が自由度[math]N-2[/math]の[math]t[/math]分布に従うことから信頼度[math](1-\alpha)[/math]の予測区間は[math] P_{lb}(x_0)[/math]を
[math]
\hat{\beta}_0+\hat{\beta}_1x_0 – t_{N-2,\alpha/2}S\sqrt{1 + \frac{1}{N} + \frac{(x_0 – \bar{x})^2}{S_{xx}}}
[/math]
とし[math]P_{ub}(x_0)[/math]を
[math]
\hat{\beta}_0+\hat{\beta}_1x_0 + t_{N-2,\alpha/2}S\sqrt{1 + \frac{1}{N} + \frac{(x_0 – \bar{x})^2}{S_{xx}}}
[/math]
として
[math]
P_{lb}(x_0) \leq Y_0 \leq
P_{ub}(x_0)
[/math]
で与えられます。慣習的に信頼度は[math]95\%, 99\%[/math]をとることが多いです。
予測区間の意味
単回帰モデルでの予測区間の意味を考えてみましょう。以下の手続きを「実験」と呼ぶことにします。
- 確率モデル[math]Y_i = \beta_0 + \beta_1 x_i + \varepsilon_i[/math]から[math]N[/math]個の値[math](x_i, y_i)[/math]を取得
- 取得した値から回帰係数[math]\hat{\beta}_0, \hat{\beta}_1[/math]を算出
- 説明変数[math]x[/math]を[math]x_0[/math]([math]x_0[/math]は任意)に固定
- 予測区間[math]\left[P_{lb}(x_0), P_{ub}(x_0)\right][/math]を計算

実験ごとに異なる予測区間[math]\left[P_{lb}(x_0), P_{ub}(x_0)\right][/math]が得られることに注意します。各実験で
予測区間[math]\left[P_{lb}(x_0), P_{ub}(x_0)\right][/math]に「観測値[math]Y_0[/math]」が含まれる
という主張は「正しい」か「誤り」のいずれかです。この実験を多数繰り返し
- 実験1回目: 誤り
- 実験2回目: 正しい
- 実験[math]M[/math]回目: 正しい
:
結果を集計した時に「正しい」割合が[math](1-\alpha)[/math]になることを予測区間は意味しています。
予測区間と信頼区間の違い
信頼区間では
誤差項を含まない真の値: [math]\beta_0 + \beta_1 x_0[/math]
が考察の対象でしたが、予測区間では
誤差項を含む目的変数の値: [math]\beta_0 + \beta_1 x_0 + \varepsilon[/math]
を対象に区間推定を行いました。その違いは区間の幅を決める項
- 信頼区間: [math]t_{N-2,\alpha/2}S\sqrt{\frac{1}{N} + \frac{(x_0 – \bar{x})^2}{S_{xx}}}[/math]
- 予測区間: [math]t_{N-2,\alpha/2}S\sqrt{1 + \frac{1}{N} + \frac{(x_0 – \bar{x})^2}{S_{xx}}}[/math]
の平方根に[math]+1[/math]を含むか含まないかとして現れます。信頼区間では[math]N[/math]が十分大きく、[math]x_0 \approx \bar{x}[/math]だと区間の幅は[math]0[/math]に近づきますが、予測区間では[math]t_{N-2,\alpha/2}S[/math]より大きくなります。
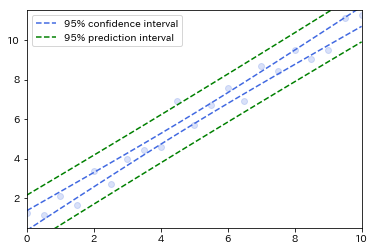
実際、予測区間は信頼区間より広いことが上図からもわかると思います。
参考文献
- Casella, G and Berger, R.L.(1990), Statistical Inference(Second Edition): Section 11.3.5 Estimation and Prediction at a Specified [math]x=x_0[/math]
シリーズ記事
「機械学習」の「教師あり学習手法」の中で最も基本的な手法として「単回帰」の性質を紹介しています。
ここでは誤差項が「独立同一な正規分布」に従うと仮定すると導ける性質として
- 最尤推定量: 最尤推定量は最小二乗推定量と一致
- 誤差の正規性チェック
- 回帰係数の有意性: 最小二乗推定量の確率分布と有意性検定を導出
- 信頼区間: 真の値の推定値が従う確率分布から信頼区間を導出
- 予測区間(本記事): 観測値が従う確率分布から予測区間を導出
を解説しています。
また、「重回帰モデル」でも同様の結果を導出できます。関心のある方は
もご参照ください。