2018年11月開催分の解答例です。
例年通り確率変数の計算、仮説検定を中心とした出題でした。ただ、単なる知識を問うだけではなく、きちんと理解できているかが問われている問題が目立ちました(問11, 18など)。
教科書の勉強だけでなく演習問題を解いたり、実際のデータで分析してみるとより理解が深まるので日頃から手を動かしておくと良いと思います。
なお、他の開催分の解答例はこちらを参照ください。
問1
[1]1985年、2017年の相対度数の合計が100%になることから(ア)=12.8%, (イ)=4.3%となり「5」が適切。
[2]箱ひげ図より最大値はA、B、Cの順に大きいのでA: 1952年、B: 1985年、C: 2017年となり「1」が適切。
[3]各記述は
- 1952年より1985年の方が四分位範囲が大きいため「誤」
- 1952年の最大値は70程度、1985年の最大値は100程度のため「誤」
- 箱ひげ図より中央値は1952, 1985, 2017年と大きくなっており「正」
より「3」が適切。
問2
[4]各記述は
- 図より60歳以降賃金が大きく下がり直線でない関係がある。このような場合、相関係数のみ判断してはいけず「正」
- 20〜54歳に限定すると直線関係が強まり相関係数は大きくなり「誤」
- 相関係数からは分からず「誤」
より「1」が適切。
問3
[5](ア)の4.98%増が111.7なので(ア)は106.4になり「1」が適切。
[6]2017年8-10月の平均値なので「4」が適切。
問4
- 基準年の価格: [math]A_i[/math]
- 比較年の価格: [math]B_i[/math]
- 基準年の数量: [math]N_i[/math]
の時、ラスパイレス指数は[math]\dfrac{\sum_i B_i N_i}{\sum_i A_iN_i}[/math]で与えられるので「2」が適切。
問5
[8]各記述は
- 各標本を独立に選ぶため「正」
- 各層からの標本サイズにより推定量の分散が単純無作為抽出より大きくなることもあるため「誤」
- 単純無作為抽出は特定層からデータが得られない可能性があり「正」
より「3」が適切。
問6
[9]二段階抽出に関する説明なので「2」が適切。
問7
[10]カモノハシがプリントされている事象を[math]p[/math]とすると
[math]
\begin{eqnarray}
P(p) &=& P(A)\times P(p | A) + P(B)\times P(p | B) \\
&=& 0.7\times 0.02 + 0.3\times 0.08 \\
&=& 0.038
\end{eqnarray}
[/math]
より「2」が適切。
[11]ベイズの定理より
[math]
\begin{eqnarray}
P(A | p) &=& \dfrac{P(A)P(p | A)}{P(p)} \\
&=& \dfrac{0.7\times 0.02}{0.038} \\
&=& 0.368
\end{eqnarray}
[/math]
なので「2」が適切。
問8
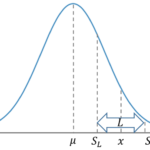
[12][math]P(U \geq -0.3 – 2x)=0.95[/math]となる[math]x[/math]を求めればよく[math]-0.3-2x=-1.65[/math]を解いて[math]x=0.67[/math]を得る。これより「4」が適切。
[13][math]x[/math]を動かすと[math]Y[/math]の分布は平行移動し上側[math]5\%[/math]点も平行移動するので「1」が適切。
問9
[14]まず[math]P(X=x)={}_{7}C_x (2/6)^x(4/6)^{7-x}[/math]であり[math]\dfrac{{}_7C_{x+1}}{{}_7C_{x}}=\dfrac{7-x}{x+1}[/math]に注意すると
[math]
\dfrac{P(X=x+1)}{P(X=x)}=\dfrac{-x+7}{2x+2}
[/math]
を得る。これより「2」が適切。
[15][math]\dfrac{P(X=x+1)}{P(X=x)}=-\dfrac{1}{2} + \dfrac{4}{x+1}[/math]と変形でき単調減少関数することがわかる。また[math]x=0, 1[/math]で1より大きく、[math]x \geq 2[/math]で1未満になるので[math]p_k=P(X=k)[/math]と書くと
[math]
p_0 < p_1 < p_2 > p_3 > \cdots
[/math]
となり「2」が適切。
問10
[16]標本平均の期待値、分散はそれぞれ[math]\mu, \sigma^2 / n[/math]なので「3」が適切。
問11
[17]正規分布の歪度、尖度はともに0なので「1」が適切。
[18]一様分布[math]U(-1, 1)[/math]の確率密度関数[math]f_U(x)[/math]は
[math]
f_U(x) = \begin{cases}
1/2 &(-1 \leq x \leq 1) \\
0 &({\rm otherwise})
\end{cases}
[/math]
であり平均[math]\mu=0[/math]である。分散[math]\sigma^2=\int x^2f_U(x)dx=1/3[/math]であり同様に3次、4次モーメントは[math]\mu_3=\int x^3f_U(x)dx=0[/math], [math]\mu_4=\int x^4f_U(x)dx=1/5[/math]である。これより尖度は[math]\mu_4/\sigma^4-3=-1.2[/math]である。以上より「5」が適切。
[19]
各記述は
- 右に裾が長い分布で歪度は正になるので「誤」
- 平坦な分布では尖度は負になるので「誤」
- [math]t[/math]分布は自由度が大きくなるにつれ正規分布に近づき尖度は0に近づくので「誤」
より「5」が適切。
問12
[20]母比率の[math]95\%[/math]信頼区間は
[math]
\hat{p}-z_{\alpha / 2}\sqrt{\frac{\hat{p}(1-\hat{p})}{n}} \leq p \leq \hat{p}+z_{\alpha / 2}\sqrt{\frac{\hat{p}(1-\hat{p})}{n}}
[/math]
で与えられるので「2」が適切。
問13
[21]母平均の検定統計量は
[math]
t = \dfrac{\bar{x} – \mu}{\sqrt{s^2/n}}
[/math]
で与えられ自由度[math]n-1[/math]の[math]t[/math]分布に従うので「4」が適切。
問14
[22]母分散の比の検定統計量は
[math]
F = \dfrac{\hat{\sigma_A}^2}{\hat{\sigma_B}^2}
[/math]
で与えられ自由度[math](n_A-1, n_B-1)[/math]の[math]F[/math]分布に従うので「5」が適切。
[23]第一種の過誤は[math]H_0[/math]が真の場合に誤って棄却してしまう確率であり、3つの組合せ(AとB, BとC、CとA)の仮説検定のいずれかで誤って棄却してしまう確率なので[math]1-0.95^3=0.14[/math]である。よって「4」が適切。
問15
[24][math]X[/math]は二項分布[math]B(200, 0.05)[/math]に従う。平均値[math]E[X]=np=10[/math], 分散[math]V[X]=np(1-p)=9.5[/math]より「3」が適切。
[25]二項分布に従う確率変数[math]X[/math]に対し帰無仮説の下で検定統計量
[math]
Z = \dfrac{X – np}{\sqrt{np(1-p)}}
[/math]
は標準正規分布に従う。[math]Z[/math]を計算すると[math]Z=1.95[/math]より[math]P[/math]値は[math]0.026[/math]になり「2」が適切。
[26]母比率の差の検定を行う。帰無仮説の下で
[math]
Z = \dfrac{\hat{p}_1 – \hat{p}_2}{\sqrt{\hat{p}(1-\hat{p})(1/n_1+1/n_2)}}
[/math]
は標準正規分布に従う。ここで[math]\hat{p}=\dfrac{n_1\hat{p}_1 + n_2\hat{p}_2}{n_1+n_2}[/math]である。これより[math]P[/math]値を求めると[math]0.86[/math]となり「5」が適切。
問16
[27]適合度検定の統計量は観測度数を[math]O_i[/math], 期待度数を[math]E_i[/math]として
[math]
\chi^2 = \displaystyle \sum_i {\dfrac{(O_i – E_i)^2}{E_i}}
[/math]
で与えられるので「1」が適切。
[28][math]\chi^2[/math]は自由度[math]n-1=5[/math]の[math]\chi^2[/math]分布に従う。[math]\chi^2[/math]分布のパーセント点表より棄却されないので「3」が適切。
問17
[29]自由度は「データ数 – 回帰係数の数」であり自由度: 52, 回帰係数の数: 3からデータ数は55になり「4」が適切。
[30]各記述は
- [math]\alpha[/math]の標準誤差は(Intercept)のStd. Errorで示されており113なので「誤」
- 各パラメタのPr(>|t|)の値は[math]5\%[/math]より小さく「正」
- 自由度調整済み決定係数はAdjusted R-squaredで示されており0.814なので「誤」
より「2」が適切。
[31]各記述は
- [math]\beta_1[/math]が負の値であり「正」
- [math]\beta_2[/math]が正の値であり「正」
- 値を代入して予測値を求めると約448になり「正」
より「4」が適切。
問18
[32]各記述は
- [math]\hat{\sigma}^2_u[/math]と残差平方和[math]S_{yy}[/math]には[math]\hat{\sigma}^2_u=\dfrac{S_{yy}}{n-2}[/math]の関係がある。ここから残差平方和を求めると1.1になり「正」
- 単位を取り替えても[math]t[/math]値は変わらないため「誤」
- 単位を取り替えると推定値のスケールも同様に変わるため「正」
より「4」が適切。
[33]各記述は
- 説明変数として必要かどうかは係数の推定値ではなく[math]t[/math]値で評価する必要があり「誤」
- 説明変数間の相関係数が高く多重共線性の影響が想定されるため「誤」
- [math]5\%[/math]より[math]P[/math]値が高いため棄却できず「誤」
より「5」が適切。
[34]各記述は
- 見かけの相関や多重共線性の影響で推定値が異なる可能性があるため「誤」
- 見かけの相関が疑われ「正」
- 有意水準[math]10\%[/math]で有意でない場合の解釈が適切ではなく「誤」
より「1」が適切。