Kaggle Titanicチュートリアル: 基礎集計編
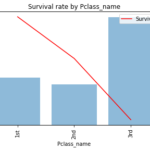
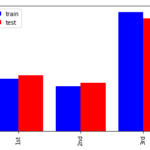
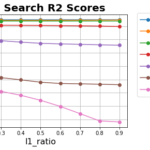
続いて学習/評価データの基礎集計をしていきます。基礎集計では 異常値(定義上、ありえない値)がないか 分布の確認 外れ値がないか 頻度の少ないデータがないか 学習、評価データで分布に偏りがないか を確認し、適切な前処理を… 続きを読む »
続いて学習/評価データの基礎集計をしていきます。基礎集計では 異常値(定義上、ありえない値)がないか 分布の確認 外れ値がないか 頻度の少ないデータがないか 学習、評価データで分布に偏りがないか を確認し、適切な前処理を… 続きを読む »
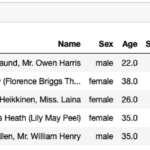
データ分析と聞くと機械学習アルゴリズムを使ったモデル構築に目がいきますが、 どのアルゴリズムが使えそうか アルゴリズムに適した形にデータ整形 するには分析対象のデータの内容をきちんと理解しておくことが重要です。そこで、分… 続きを読む »
ここでは分析を始めるために必要な 学習/評価データのダウンロード 分析環境準備 について説明します。 学習/評価データのダウンロード 「Data」のページに行くと データ定義と説明 学習/評価データと予測結果のサンプル … 続きを読む »
ここではKaggle Titanicチュートリアルを始めるにあたって必要な Kaggleアカウントの作成/サインイン Titanicチュートリアルの内容/ルール確認 について説明します。 Kaggleのアカウント作成/サ… 続きを読む »
数値データを適当な境界で区切りカテゴリデータ化することをビン分割(binning)と呼びます。例えば「年齢」をざっくり「年代」としてみることで傾向が捉えやすくなるなど機械学習ではよく行われる前処理の一つです。 panda… 続きを読む »
分析環境の定番であるJupyter notebookで 分析処理を実行するマシン(サーバ側) 分析結果を確認するマシン(クライアント側) と分けて運用する方法を紹介します。 私の場合だとパラメタチューニングで大量の並列処… 続きを読む »
Anacondaにはcondaという環境管理機能が用意されており用途に応じてPython環境を使い分けることができます。(仮想環境の構築/管理方法は「AnacondaでのPython仮想環境の構築」を参照ください。) こ… 続きを読む »
画像セグメンテーション(Semantic segmentation)技術として注目を集めている「Mask R-CNN」をMacで動かす機会があったのでその手順を紹介します。 Python3, TensorFlow, Ke… 続きを読む »
物体検知(object detection)アルゴリズムとして有名なYOLO(You Only Look Once)のバージョンが上がりYOLO V3がリリースされました。YOLO V2も高速/高精度でしたがさらなる高速… 続きを読む »
Anacondaにはcondaという環境管理機能が用意されており用途に応じてPython環境を使い分けることができます。 特にDeep Learning系のフレームワークは関連モジュールを特定バージョンに揃えておく必要が… 続きを読む »