UbuntuでDataFrameのto_clipboardが使えない時の対処法
PandasのDataFrameのデータを とするとタブ区切りのデータをクリップボードにコピーできます。 手軽に表計算ソフトなどで利用でき便利な機能ですがUbuntu 20.04 LTSで試したところ特にエラーがでないも… 続きを読む »
PandasのDataFrameのデータを とするとタブ区切りのデータをクリップボードにコピーできます。 手軽に表計算ソフトなどで利用でき便利な機能ですがUbuntu 20.04 LTSで試したところ特にエラーがでないも… 続きを読む »
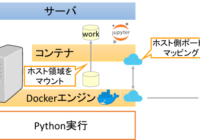
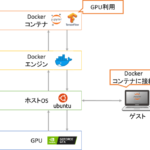
「AnacondaでのPython仮想環境の構築」で紹介したように利用目的に応じてPython環境を切り分けることができます。ただ、GPU環境を構築する場合にドライバやCUDAなど開発環境を含めて切り分けるにはDocke… 続きを読む »
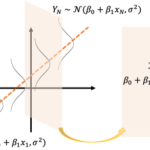
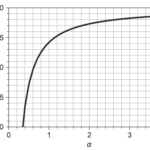
前回の記事ではロジスティック回帰モデルで生存者予測を行いました。 ロジスティック回帰モデルは「目的変数(生存しやすさ)を特徴量の重み付けで表現しモデルの可読性が高い」という利点がある一方で 目的変数と特徴量の間には「単調… 続きを読む »
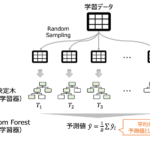
単変量モデル編では特徴量ごとにロジスティック回帰モデルを構築し精度評価を行いました。ここでは7つの特徴量を使って生存者を予測するモデルを構築します。 今までのモデルと比べ 互いに相関のある複数の特徴量を用いる モデルのハ… 続きを読む »
ベースラインモデル編では「Majority classifier」を構築しました。Majority classifierは特徴量を1つも用いずすべて「死亡」と予測するモデルでしたが、ここでは特徴量を1つだけ用いる単変量モ… 続きを読む »
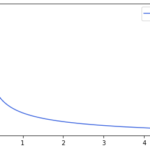
シミュレーションをする際など指定した確率で要素を生成したいことがあります。例えば天気に基づいた売上をシミュレーションする際に天気を 晴: 確率50% 曇: 確率35% 雨: 確率15% で生成したい場合などです。ここでは… 続きを読む »
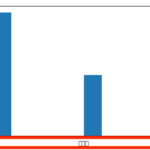
MacでAnacondaを使ってPython環境を構築しMatplotlibでグラフを描画すると日本語が文字化けしてしまいます。 上の図の赤枠のように日本語部分が文字化けして「□」になっています。これはMatplotli… 続きを読む »
いよいよ機械学習モデル構築に入っていきます。高度なモデルを使いたくなりますが 仮定、前提が多く「うまく動かない」「精度がでない」ことがある エラーや精度が出ない時の原因特定が大変 なのでシンプルなモデルから始めて徐々に高… 続きを読む »
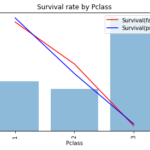
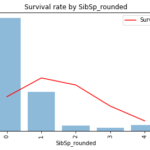
引き続き特徴量と生存率の関係を見ていきます。前半編でも触れたように 特徴量の変化によって生存率に差がでるか? 特徴量の変化に対して生存率が上下したり非単調な変化をしていないか? を確認します。なお、Jupyter not… 続きを読む »
さぁここから年齢、性別などの特徴量と生存率の関係を見ていきます。基本的には 特徴量の変化によって生存率に差がでるか? 特徴量の変化に対して生存率が上下したり非単調な変化をしていないか? を確認します。特徴量生成の重要ポイ… 続きを読む »