単回帰モデルでの予測の留意点
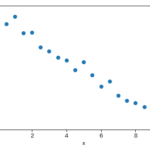
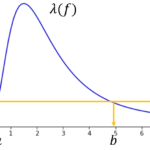
単変量線形回帰(単回帰)モデルは学習データ外の値や外れ値で予測した場合 意味のない値 大きく外れた値 になる可能性があり注意が必要です。ここでは単回帰モデルの予測の留意点、対処法を説明します。 学習データ外での予測の留意… 続きを読む »
単変量線形回帰(単回帰)モデルは学習データ外の値や外れ値で予測した場合 意味のない値 大きく外れた値 になる可能性があり注意が必要です。ここでは単回帰モデルの予測の留意点、対処法を説明します。 学習データ外での予測の留意… 続きを読む »
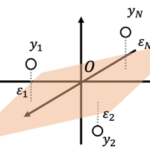
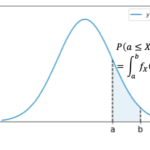
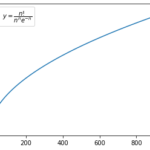
「単回帰の考え方と基本的な性質」に続き学習データへの当てはまりの良さを表す「決定係数」を紹介し、単回帰モデルでの決定係数と相関係数の関係を導きます。 決定係数 決定係数(coefficient of determinat… 続きを読む »
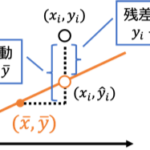
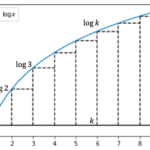
教師あり学習の最も基本的な手法として単回帰の考え方と基本的な性質として 回帰係数の導出 回帰直線の性質 計算量 を紹介します。 単回帰 単回帰は[math]N[/math]個の 説明変数: [math]x_i\in \m… 続きを読む »
いよいよ機械学習モデル構築に入っていきます。高度なモデルを使いたくなりますが 仮定、前提が多く「うまく動かない」「精度がでない」ことがある エラーや精度が出ない時の原因特定が大変 なのでシンプルなモデルから始めて徐々に高… 続きを読む »
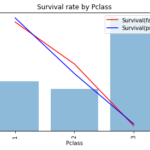
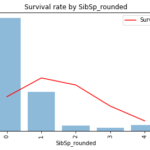
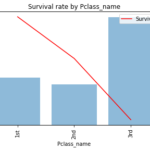
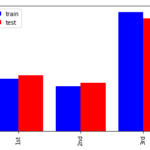
引き続き特徴量と生存率の関係を見ていきます。前半編でも触れたように 特徴量の変化によって生存率に差がでるか? 特徴量の変化に対して生存率が上下したり非単調な変化をしていないか? を確認します。なお、Jupyter not… 続きを読む »
さぁここから年齢、性別などの特徴量と生存率の関係を見ていきます。基本的には 特徴量の変化によって生存率に差がでるか? 特徴量の変化に対して生存率が上下したり非単調な変化をしていないか? を確認します。特徴量生成の重要ポイ… 続きを読む »
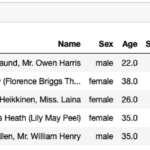
続いて学習/評価データの基礎集計をしていきます。基礎集計では 異常値(定義上、ありえない値)がないか 分布の確認 外れ値がないか 頻度の少ないデータがないか 学習、評価データで分布に偏りがないか を確認し、適切な前処理を… 続きを読む »
データ分析と聞くと機械学習アルゴリズムを使ったモデル構築に目がいきますが、 どのアルゴリズムが使えそうか アルゴリズムに適した形にデータ整形 するには分析対象のデータの内容をきちんと理解しておくことが重要です。そこで、分… 続きを読む »
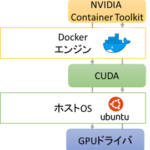
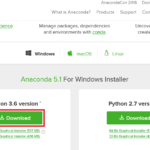
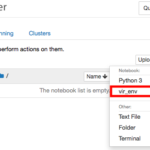
ここでは分析を始めるために必要な 学習/評価データのダウンロード 分析環境準備 について説明します。 学習/評価データのダウンロード 「Data」のページに行くと データ定義と説明 学習/評価データと予測結果のサンプル … 続きを読む »
ここではKaggle Titanicチュートリアルを始めるにあたって必要な Kaggleアカウントの作成/サインイン Titanicチュートリアルの内容/ルール確認 について説明します。 Kaggleのアカウント作成/サ… 続きを読む »