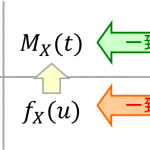
確率変数の相関係数
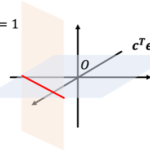
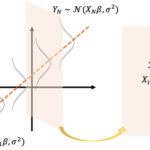
2つの確率変数が直線関係があるかを示す指標として相関係数(correlation coefficient)があります。 単に「相関係数」という場合には2つのデータ系列[math](x_i,\ y_i),\ i=1,\do… 続きを読む »
2つの確率変数が直線関係があるかを示す指標として相関係数(correlation coefficient)があります。 単に「相関係数」という場合には2つのデータ系列[math](x_i,\ y_i),\ i=1,\do… 続きを読む »
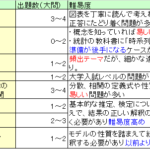
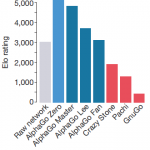
2018年6月開催分の解答例です。前回に続き今回も仮説検定や区間推定からの出題が多くありました。内容も 定義を正確に暗記 統計量等を正確に算出 算出結果を適切に評価 できることが要求されており難度が高いです。今後もこの傾… 続きを読む »

AIビジネスの法律実務 AIはどうしても「技術的にこんなことができる」という話が先行しますが、ビジネス活用にあたっては AIを構築する際の第三者が著作権を持つ学習データを利用してよいのか 構築したAIをどう権利保護するか… 続きを読む »
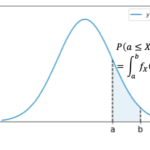
調査から得たデータは4つの尺度水準 名義尺度 順序尺度 間隔尺度 比例尺度 に分けられます。 データに対して可能な演算(ex. 足し算、掛け算や平均を取るなど)は尺度水準に依存し、要約統計量や検定法は尺度水準に応じて適切… 続きを読む »
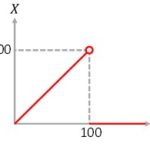
数値データを適当な境界で区切りカテゴリデータ化することをビン分割(binning)と呼びます。例えば「年齢」をざっくり「年代」としてみることで傾向が捉えやすくなるなど機械学習ではよく行われる前処理の一つです。 panda… 続きを読む »

実践 金融データサイエンス 隠れた構造をあぶり出す6つのアプローチ 本書では金融におけるデータ分析がビッグデータ/AIの発展でどのように進化したかを紹介しています。金融系のお客様と仕事する機会があり読んだのですが最近の動… 続きを読む »

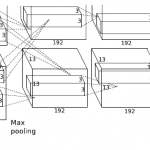
TensorFlowで学ぶディープラーニング入門 ~畳み込みニューラルネットワーク徹底解説~
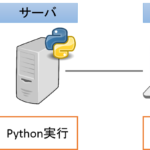
分析環境の定番であるJupyter notebookで 分析処理を実行するマシン(サーバ側) 分析結果を確認するマシン(クライアント側) と分けて運用する方法を紹介します。 私の場合だとパラメタチューニングで大量の並列処… 続きを読む »
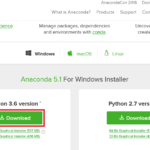
Anacondaにはcondaという環境管理機能が用意されており用途に応じてPython環境を使い分けることができます。(仮想環境の構築/管理方法は「AnacondaでのPython仮想環境の構築」を参照ください。) こ… 続きを読む »
良質かつ大規模な画像データセットの代名詞でもあるImageNetを使った画像認識コンペティションがImageNet Large Scale Visual Recognition Challenge(ILSVRC)です。 … 続きを読む »